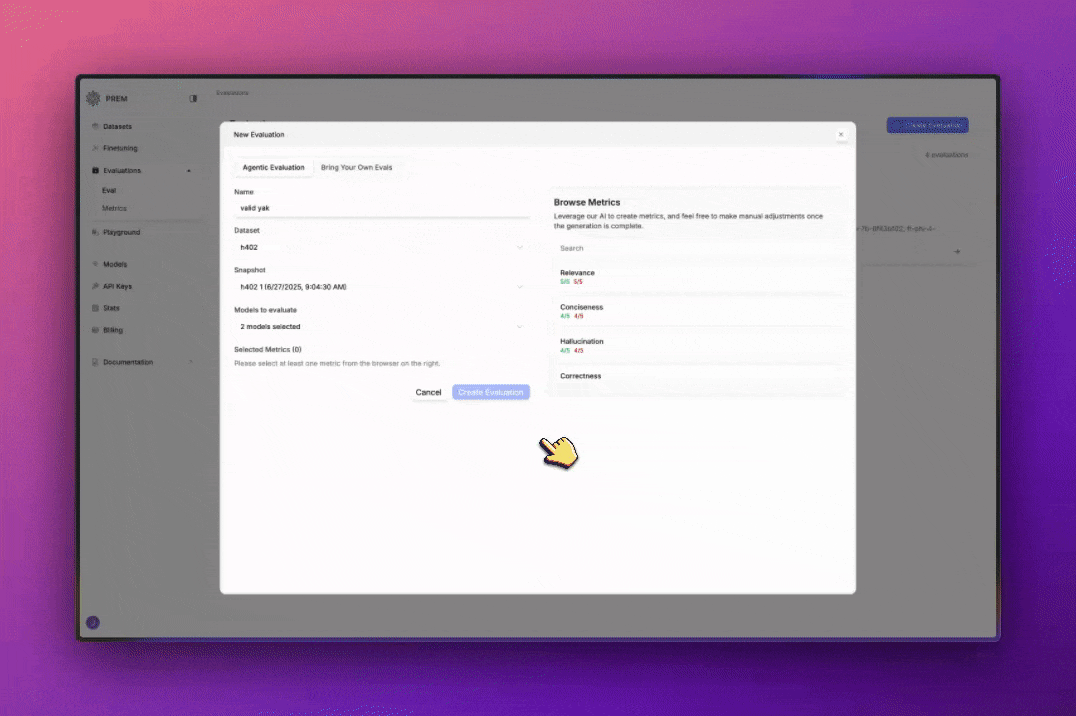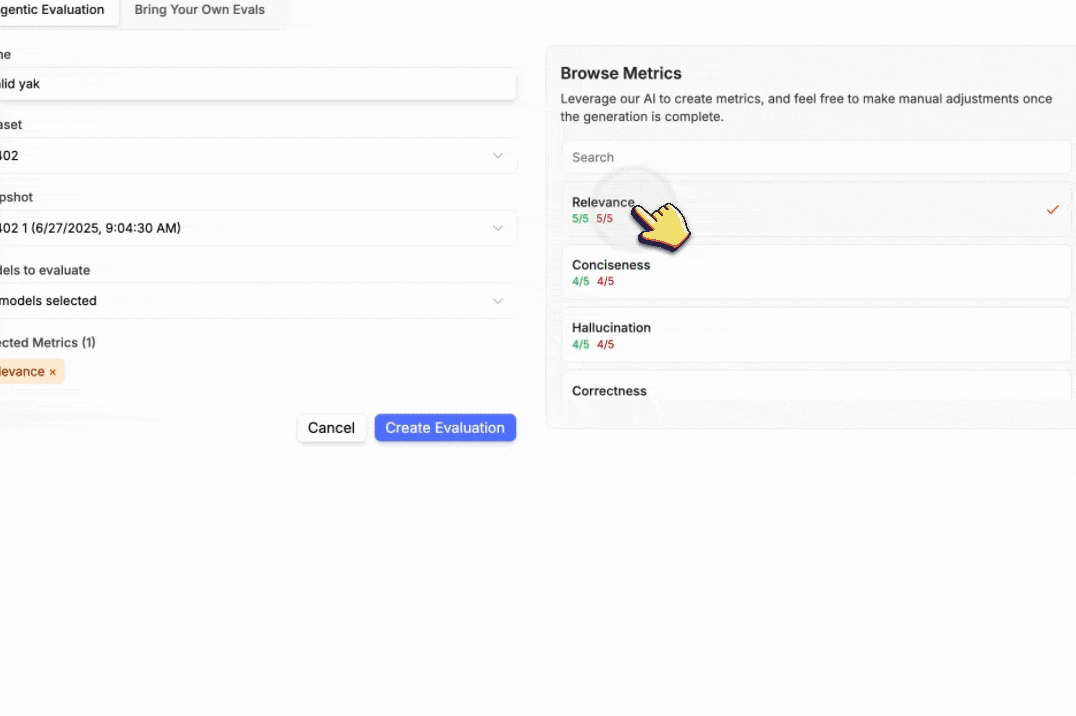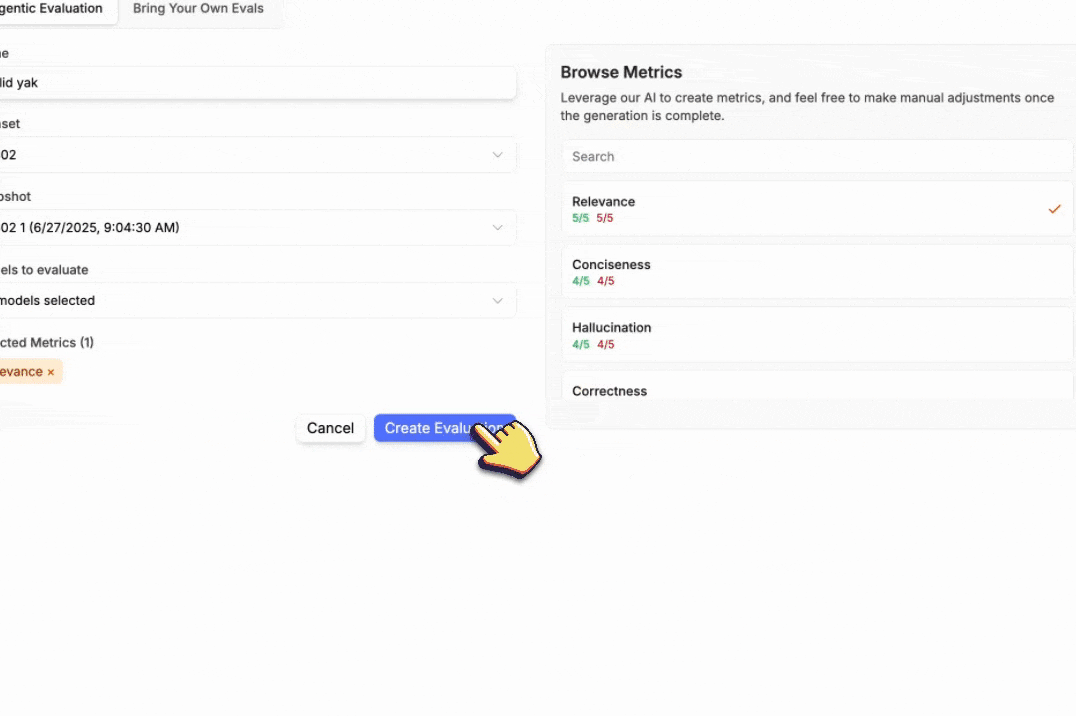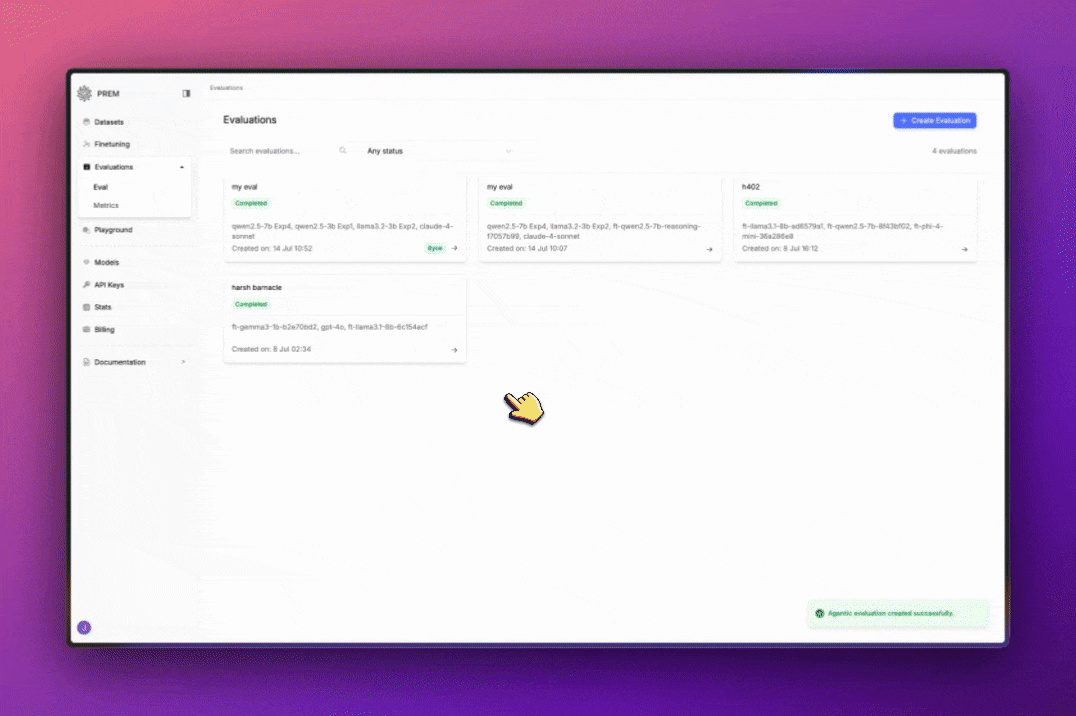
- Correctness: Measures the factual accuracy and correctness of the response
- Conciseness: Measures how concise and to-the-point the response is without unnecessary information
- Hallucination: Measures whether the response contains made-up or fabricated information
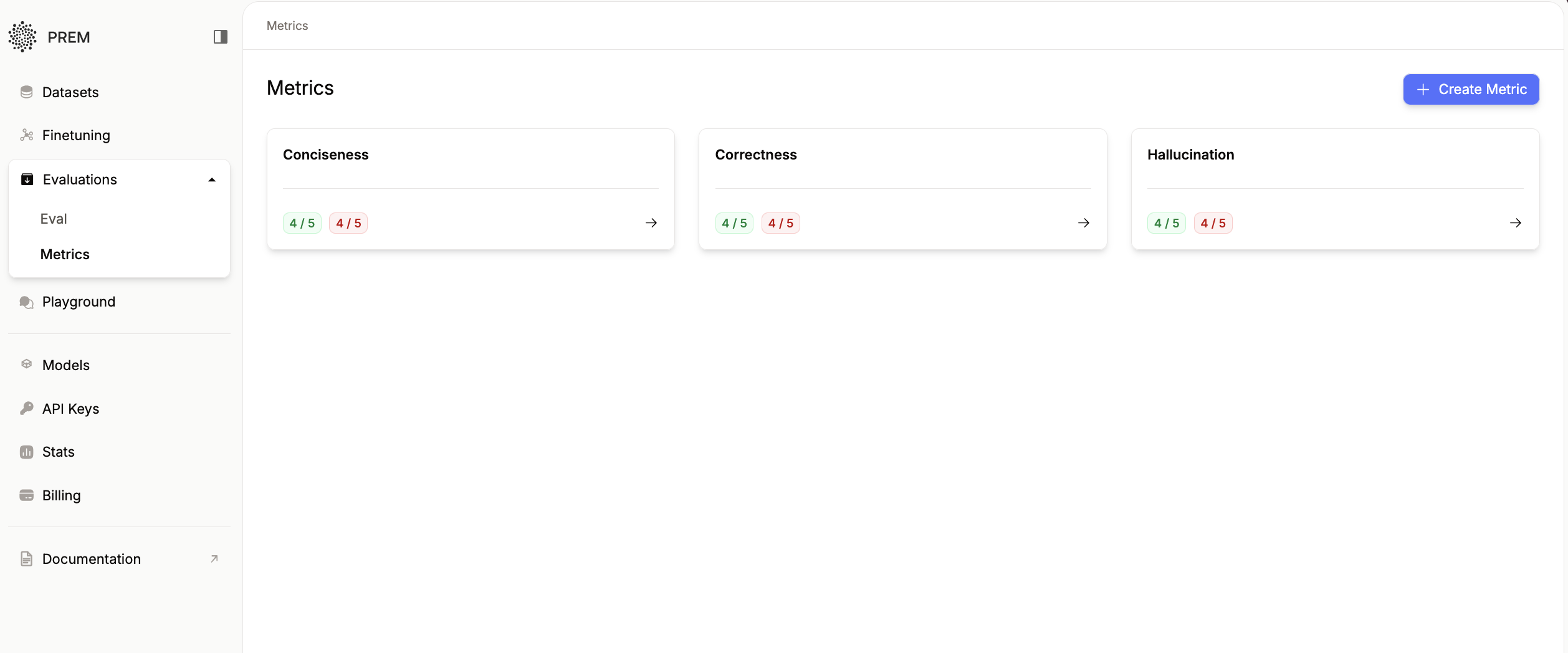 Each metric has its own defined rules. In case of metrics like: token-accuracy has code based rules. For metrics like above, we have natural language conditioned rules called Rubrics.
Each metric has its own defined rules. In case of metrics like: token-accuracy has code based rules. For metrics like above, we have natural language conditioned rules called Rubrics.
Evaluation Rules
You can edit evaluation metrics by rules the LLM should follow and rules the LLM should not follow. Just hover over each rule, and click on the pencil icon to edit it. When you’re done, click on the checkmark icon to save your changes.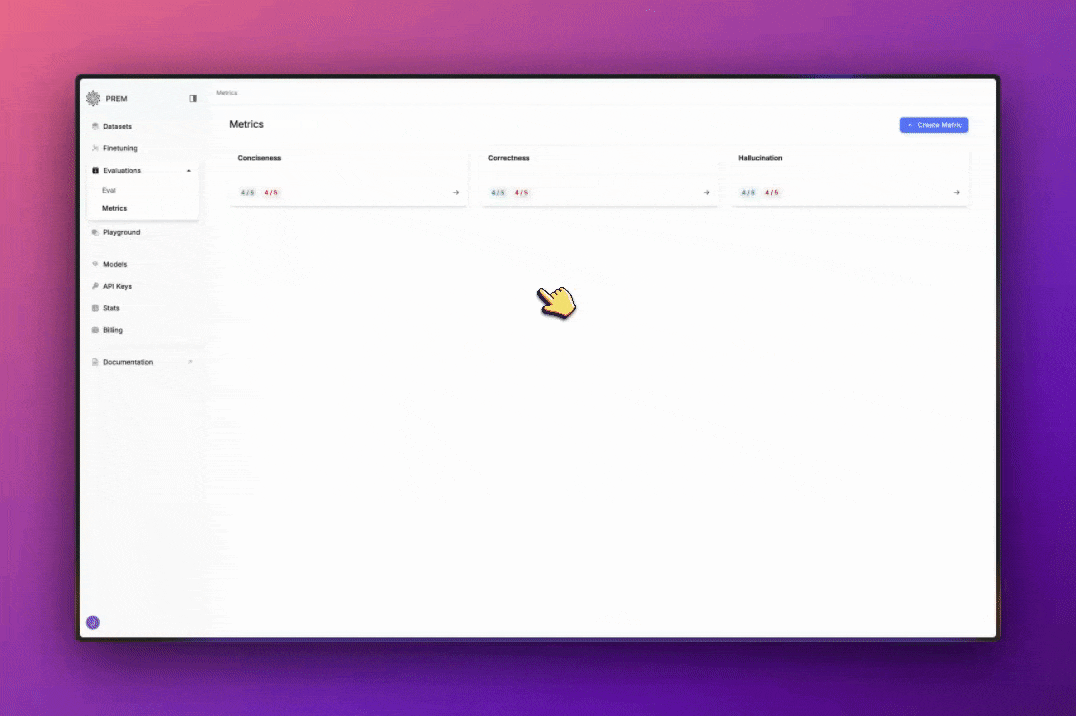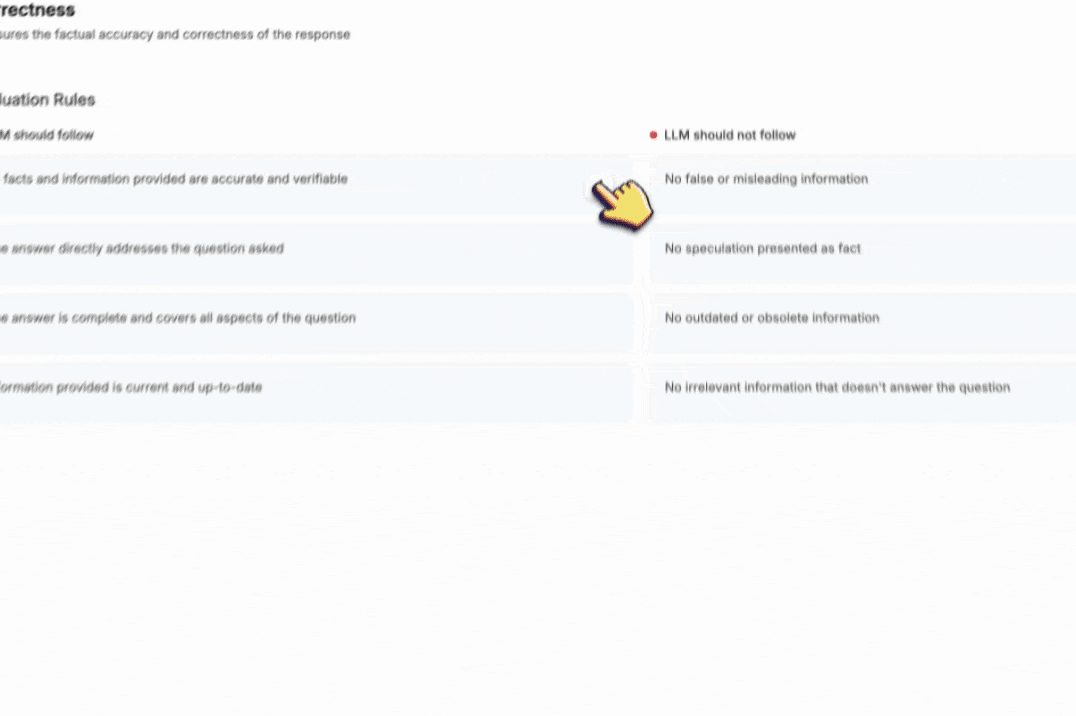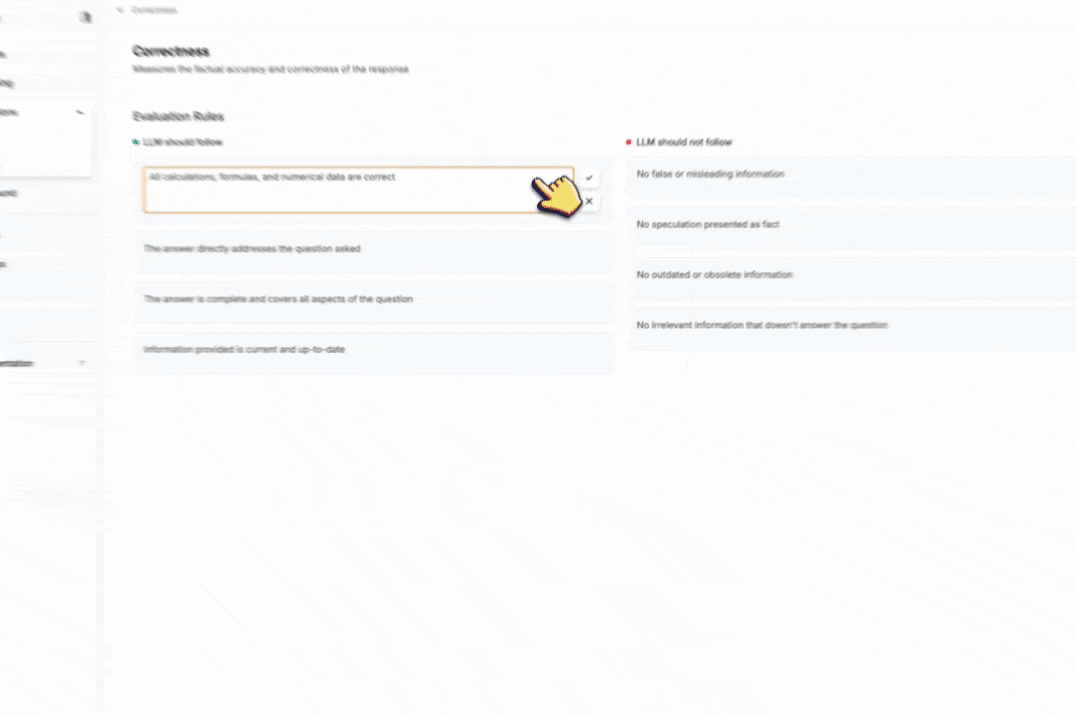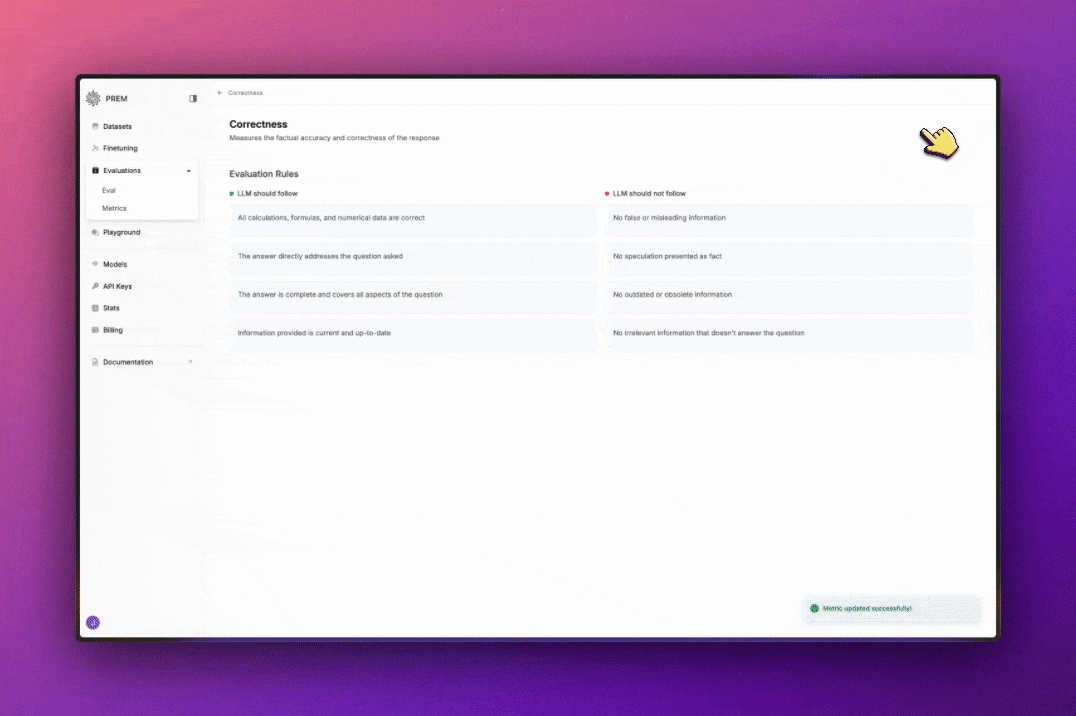
Create Your Own Metrics
You can create your own metrics by clicking on the Create Metric button.- Give your metric a name
- Write a description for your metric
- Click Generate Rules to generate the rules for your metric
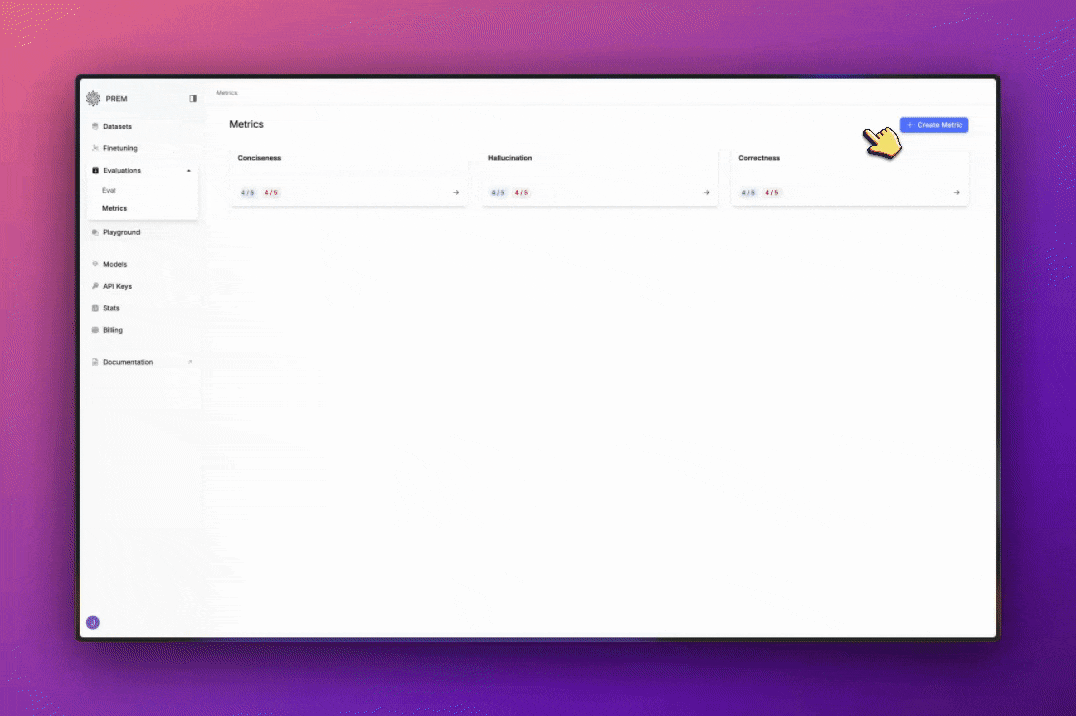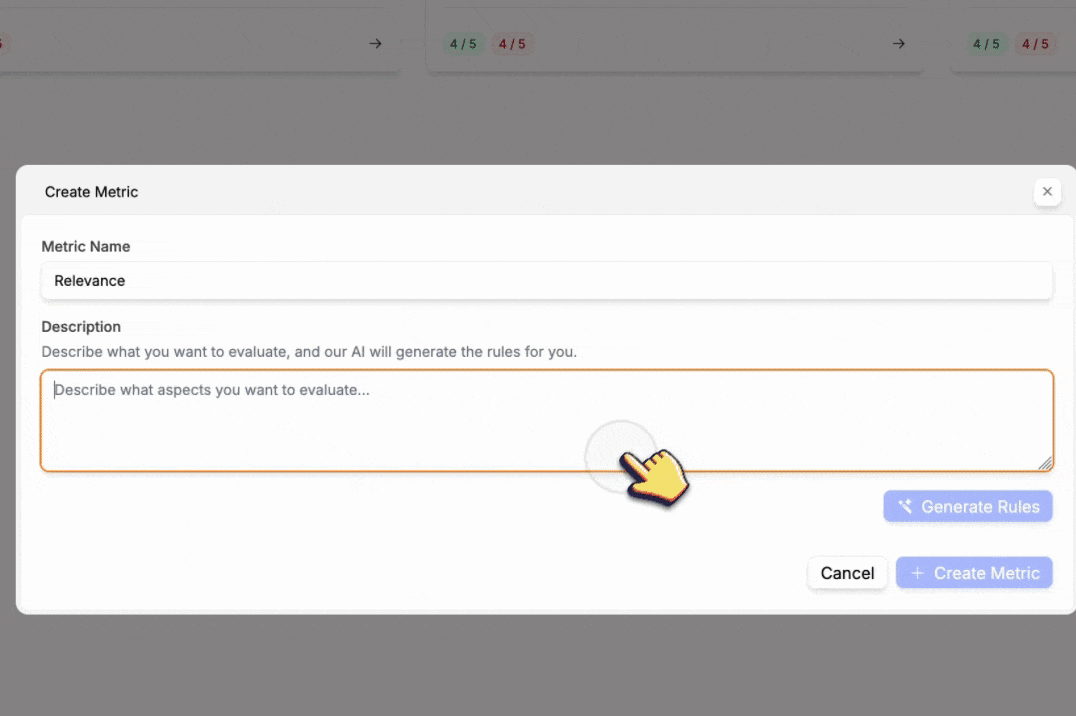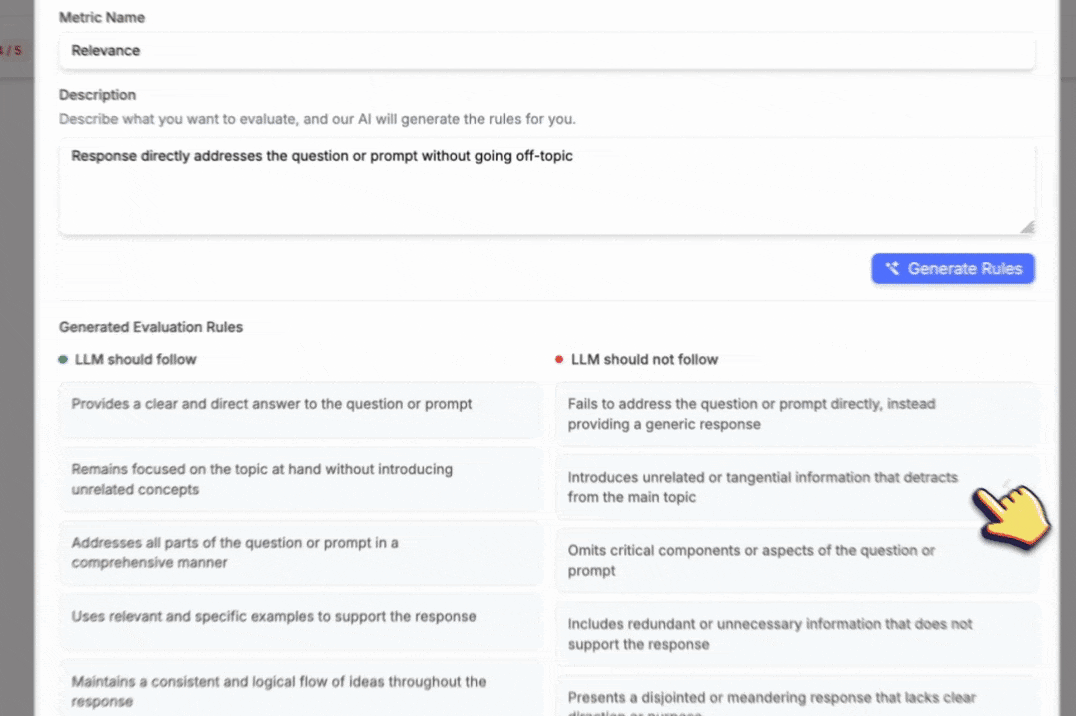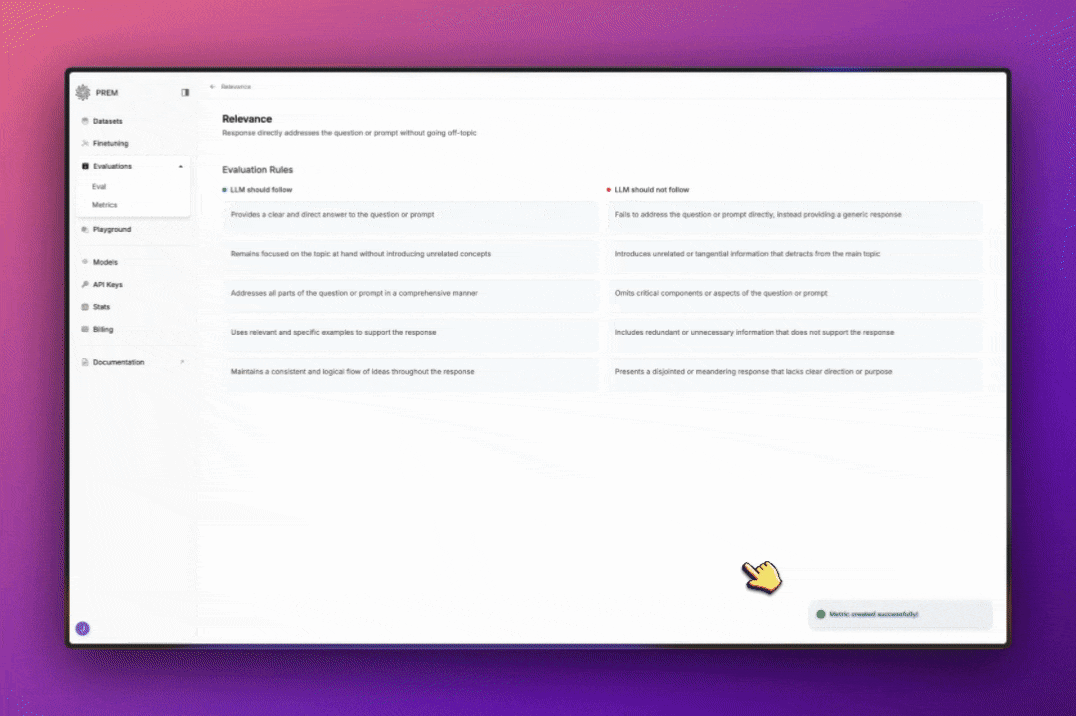 So now when you are creating a new evaluation, you can select your custom metric from the list.
So now when you are creating a new evaluation, you can select your custom metric from the list.