

What are Good Metrics
Good metrics are the foundation of reliable LLM evaluation. Unlike traditional ML metrics that focus on numerical accuracy, effective LLM metrics define precise quality standards using natural language rules that align with real-world requirements. In Prem’s Agentic Evaluation system, metrics are composed of rubrics - structured rules that specify exactly what constitutes good output. These rubrics transform subjective quality judgments into consistent, automated checks that provide transparent, actionable feedback.Why Good Metrics Matter
When LLMs move from development to production, evaluation becomes critical for:- Risk mitigation - Catching failures before they reach users
- Model accountability - Understanding exactly why outputs succeed or fail
- Production readiness - Ensuring models meet business and compliance requirements
- Continuous improvement - Identifying specific areas for enhancement
Writing Effective Metrics
Start by articulating what “good” looks like in plain language. Be specific about: Positive rules (what the output should include):- “Output must contain all relevant ingredients”
- “Response should be in a professional, helpful tone”
- “Answer must cite specific sources when making claims”
- “No duplicate items allowed”
- “Avoid technical jargon or overly complex language”
- “Do not include unrelated information”
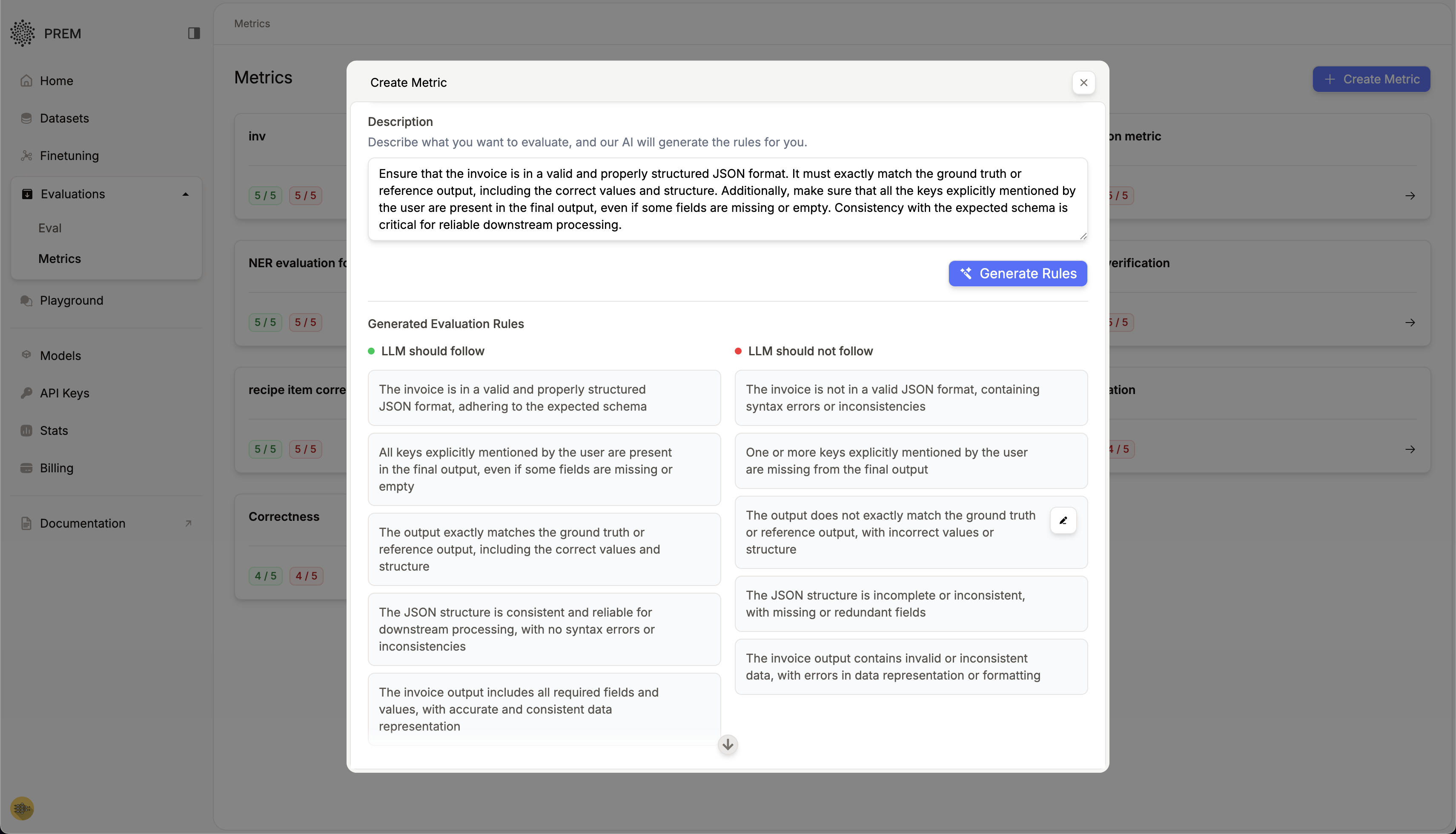
The best part is, you do not have to write this positive or negative rules. Prem’s intelligence will do it for you.
Write metrics as if you’re instructing a human evaluator. The clearer your natural language description, the better Prem’s system can translate it into automated checks.
Best Practices for Metric Design
Focus on Business Impact
Align metrics with real-world consequences. For customer support bots, prioritize helpfulness and accuracy over perfect grammar.Test Edge Cases
Include rules that catch common failure modes:- Empty responses
- Formatting errors
- Off-topic content
- Inappropriate tone
Keep It Maintainable
Start simple and add complexity gradually. A few well-defined rules often outperform dozens of unclear ones.Validate with Examples
Test your metrics on known good and bad examples to ensure they capture the right behaviors.Common Metric Examples
Format Validation:The output must be a syntactically valid JSON object. It should include all required fields: “summary”, “key_points”, and “confidence_score”. Make sure the structure adheres to JSON standards—no trailing commas, missing brackets, or malformed types. This ensures smooth integration with downstream tools expecting a consistent schema.
The summary must accurately reflect the main themes and important information from the source text. Avoid introducing any unsupported claims, speculations, or personal interpretations. The content should remain grounded in the original material and aim to be as informative and objective as possible.
The response should maintain a professional and neutral tone throughout. Use clear, concise language and prefer active voice to passive constructions. Avoid technical jargon unless explicitly required for the context, and aim for maximum readability and accessibility across varied audiences.
Ensure that all relevant information—such as dates, names, and locations mentioned in the input—is correctly extracted and included. Do not omit any key entities, and refrain from adding fictional or inferred details not present in the source. The output should be a faithful and complete representation of the original content.
Good metrics transform evaluation from a black box into a transparent, improvement-focused process. By defining clear quality standards upfront, you enable continuous model refinement and build the foundation for trustworthy AI deployment.