

What is LoRA
LoRA, or Low-Rank Adaptation, is a technique designed to make fine-tuning Large Language Models (LLMs) much more efficient. In traditional fine-tuning, you have to update all the parameters of an LLM, which can be slow and resource-intensive. With LoRA, instead of changing the entire model, you add a few small, trainable components to the base LLM. These components are trained for your specific task, allowing the model to adapt quickly without needing to retrain everything from scratch.When to use LoRA
Because LoRA only updates a small part of the model, it’s much faster than standard fine-tuning. As a general rule, if regular fine-tuning of an LLM on a large dataset would take around 30 minutes, LoRA can often get the job done in 10 minutes or less. This makes it a great choice when you want to adapt a model quickly and efficiently, without needing deep expertise in machine learning. Below is a table comparing when to use LoRA versus full fine-tuning:| Scenario | LoRA | Full Fine-tuning | Real-world Example |
|---|---|---|---|
| Quick adaptation 🚀 | ✅ | ❌ | Customizing a chatbot for your company’s tone and style |
| Limited computational resources 💻 | ✅ | ❌ | Small startup fine-tuning on a laptop or basic GPU |
| Small to medium datasets 📊 | ✅ | ❌ | Training on 1,000-10,000 customer support tickets |
| Fast experimentation 🧪 | ✅ | ❌ | Testing different prompt styles for marketing content |
| Domain-specific tasks 🎯 | ✅ | ⚠️ | Adapting a model for legal document analysis |
| Massive datasets 📈 | ❌ | ✅ | Training on millions of medical research papers |
| Fundamental behavior change 🔄 | ❌ | ✅ | Teaching a general model to code in a new programming language |
| Maximum performance 🏆 | ⚠️ | ✅ | Building a state-of-the-art translation system |
| Budget constraints 💰 | ✅ | ❌ | Bootstrapped companies with limited cloud computing budget |
| Time-sensitive projects ⏰ | ✅ | ❌ | Launching a customer service bot in a week |
Using LoRA in Prem Studio
1
Create a New Fine-Tuning Job
 To get started, click the + Create Fine-Tuning Job button in the top right corner of the page.
Fill in the name and select your dataset. Once you’ve configured these settings, click the Create Fine-Tuning Job button.
To get started, click the + Create Fine-Tuning Job button in the top right corner of the page.
Fill in the name and select your dataset. Once you’ve configured these settings, click the Create Fine-Tuning Job button.2
Configure Your LoRA Settings
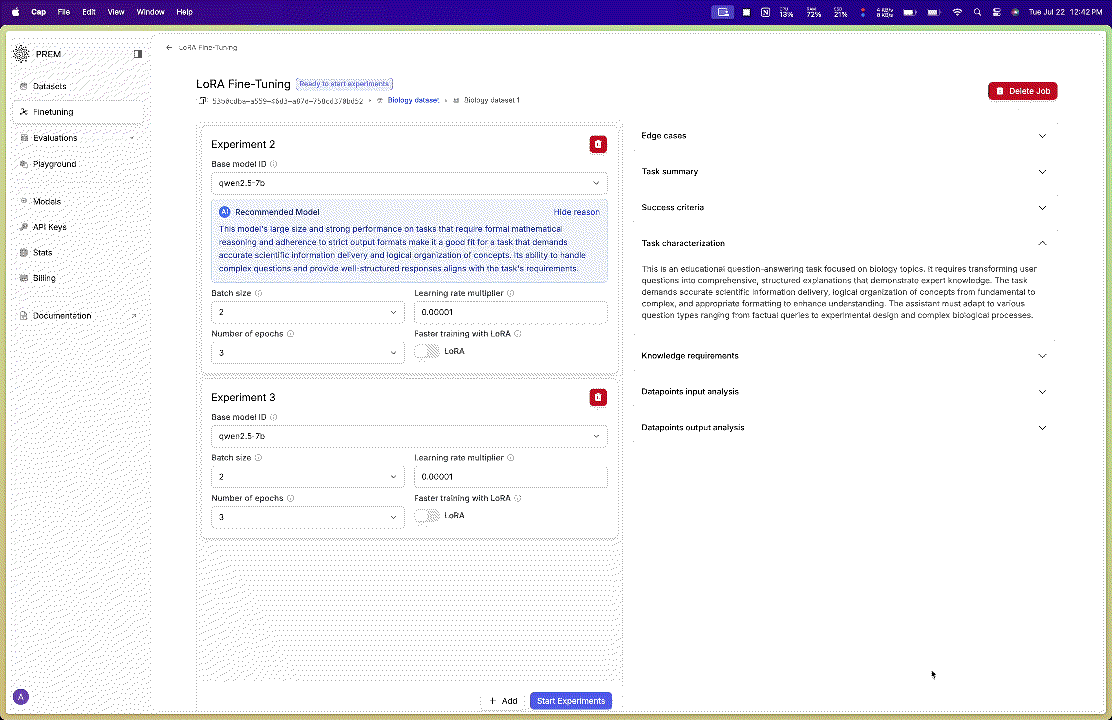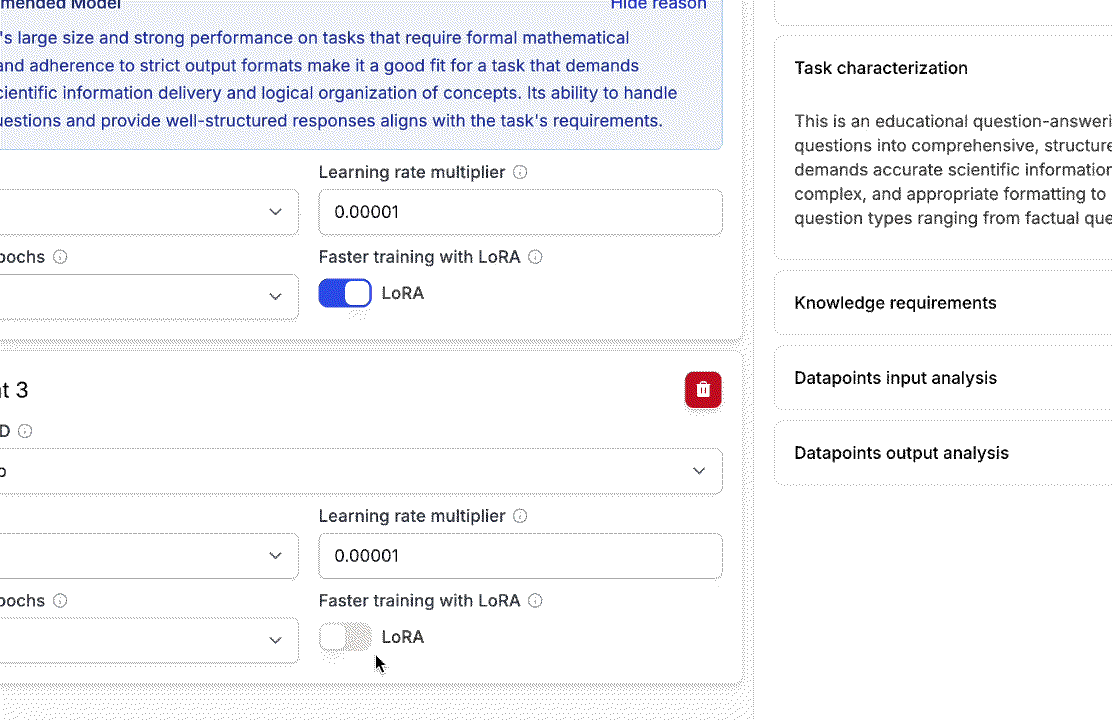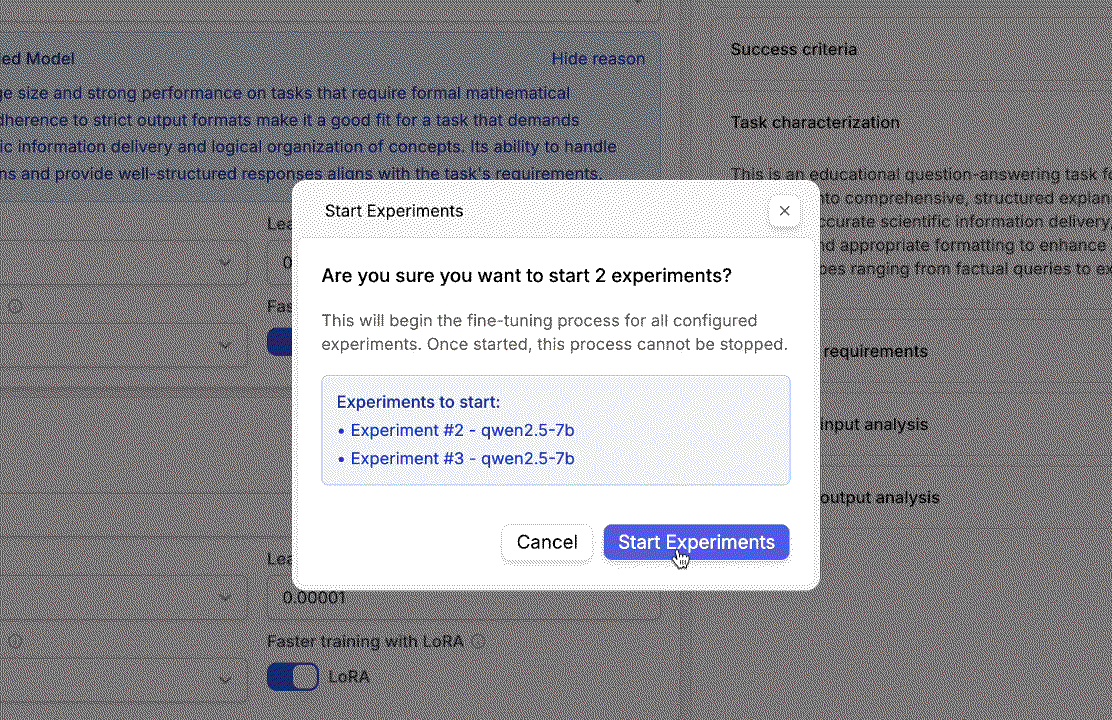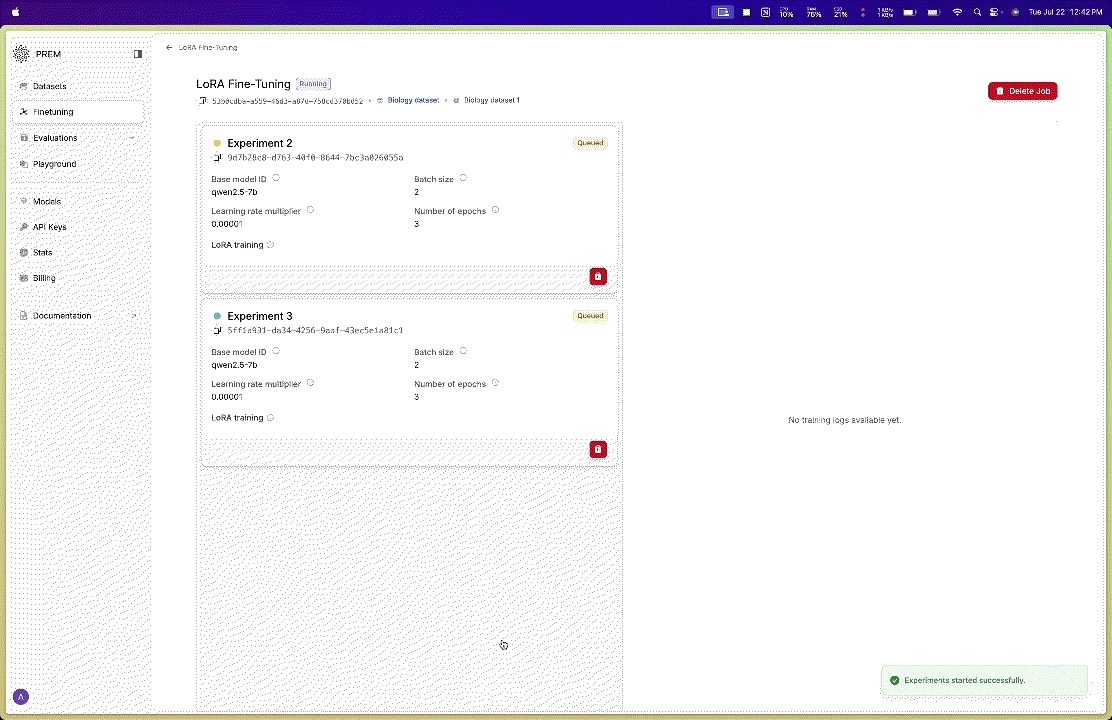
- Choose the model you want to fine-tune and toggle on the LoRA option.
- Click the Start Experiments button.
- A confirmation dialog will appear asking you to confirm starting the experiments.
For complex tasks, you may need to increase the number of epochs to achieve the best results.