

General
Upload Datasets and Models to Hugging Face
Learn how to upload Prem datasets and finetuned models to Hugging Face
Prem Studio offers seamless integration with Hugging Face. Whether you upload your own datasets, generate new ones, or fine-tune models using various techniques, you can easily export your final dataset snapshots and finetuned models directly to Hugging Face.
 In the top right of the datasets page, you will see a Snapshots button. Click it to view a list of available snapshots. Download the snapshot of your choice by clicking the download icon.
This will download a zip file to your Now that you have your dataset files, you’ll need to use Python to upload them to Hugging Face. The code below loads your dataset files and creates a proper Hugging Face dataset structure with multiple splits (train, validation, and full).Copy this Python code, which loads your dataset and uploads it to Hugging Face. Remember to provide the correct path to your dataset files. You can upload all three splits (train, validation, and full) or just the ones you need.
In the top right of the datasets page, you will see a Snapshots button. Click it to view a list of available snapshots. Download the snapshot of your choice by clicking the download icon.
This will download a zip file to your Now that you have your dataset files, you’ll need to use Python to upload them to Hugging Face. The code below loads your dataset files and creates a proper Hugging Face dataset structure with multiple splits (train, validation, and full).Copy this Python code, which loads your dataset and uploads it to Hugging Face. Remember to provide the correct path to your dataset files. You can upload all three splits (train, validation, and full) or just the ones you need.
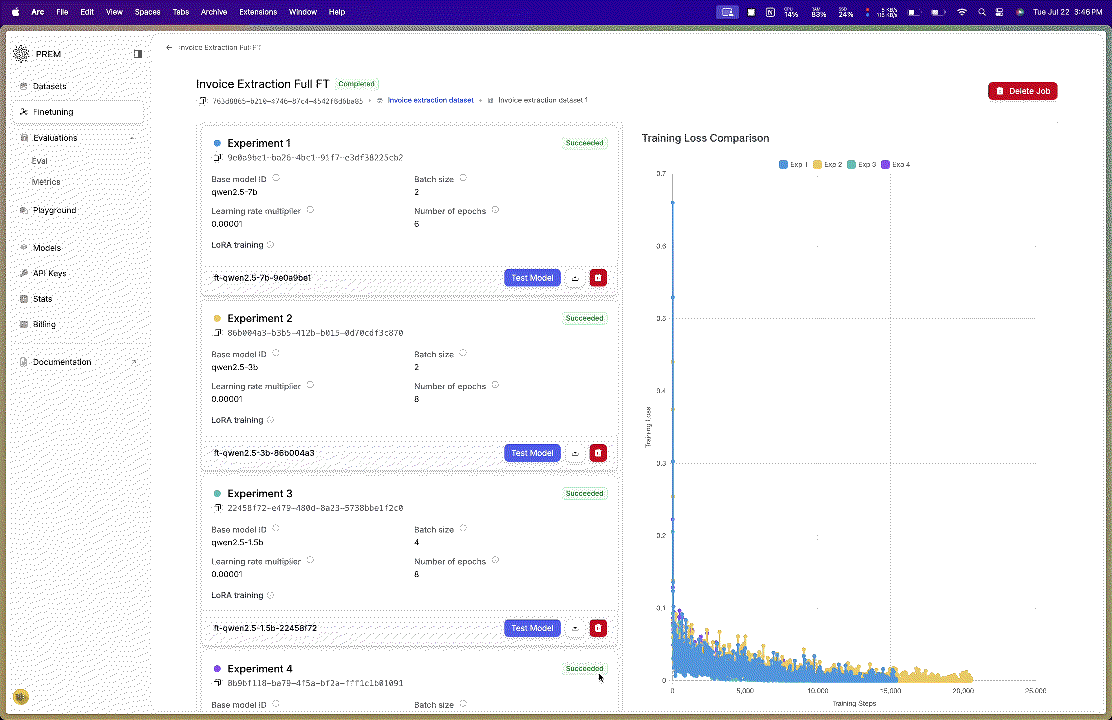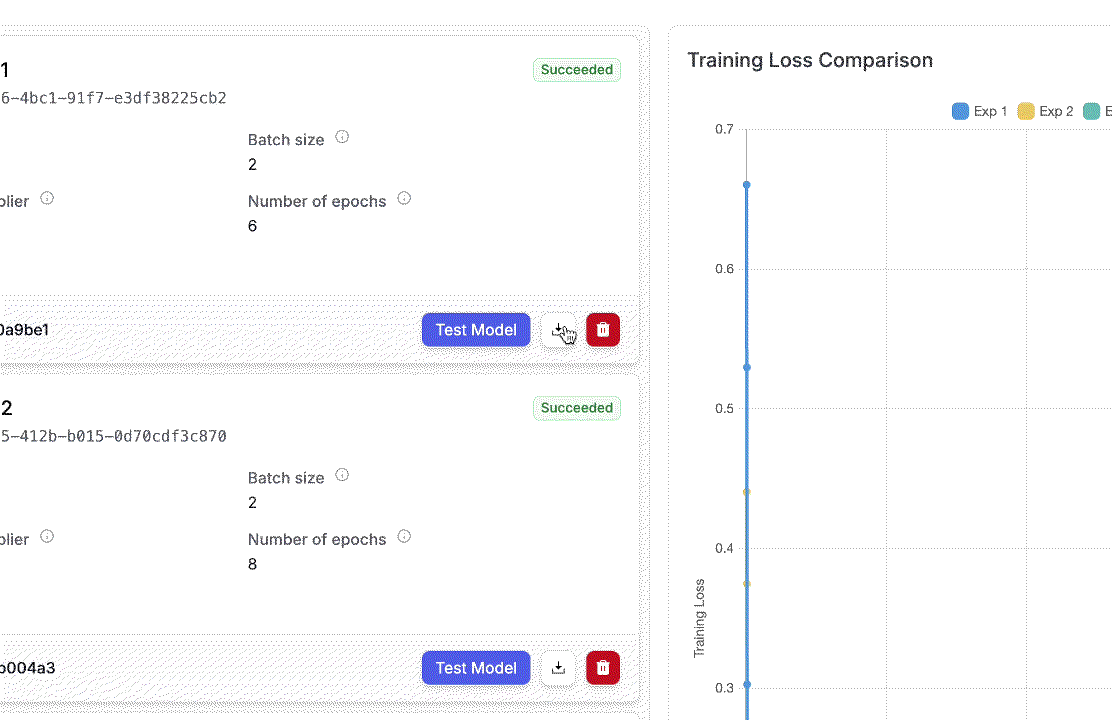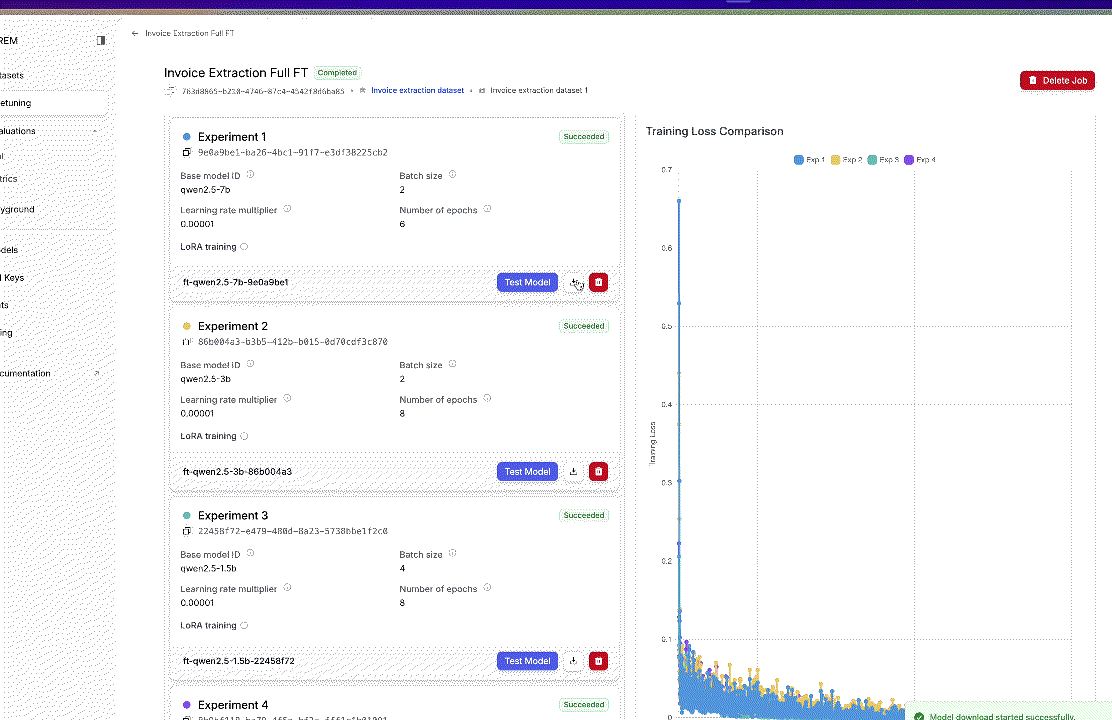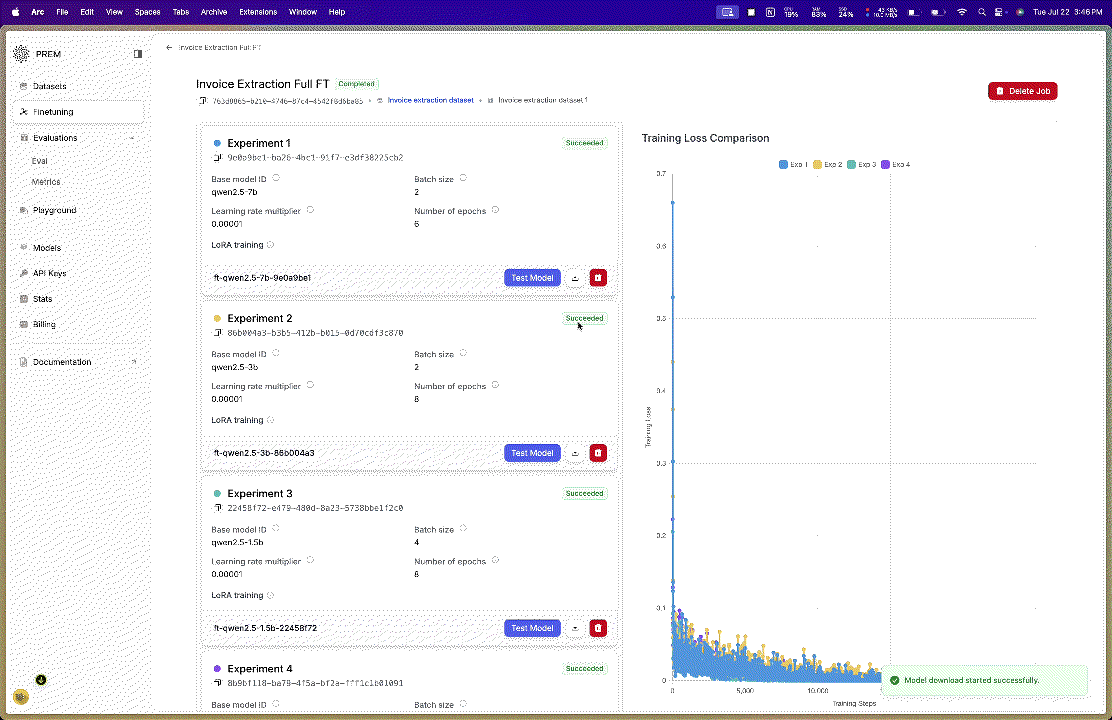 In this guide, we’ll show you how to upload model checkpoints fine-tuned using both LoRA and full fine-tuning methods.
In this guide, we’ll show you how to upload model checkpoints fine-tuned using both LoRA and full fine-tuning methods.
Uploading Prem Datasets to Hugging Face
Let’s start with uploading datasets to Hugging Face. By now you might have learned that you can store versions of datasets in the form of snapshots. Let’s see how we can download the snapshot and upload it to Hugging Face.1
Download Your Dataset Snapshot
In the top right of the datasets page, you will see a Snapshots button. Click it to view a list of available snapshots. Download the snapshot of your choice by clicking the download icon.
This will download a zip file to your Downloads folder. When you unzip it, you will see three files:
train.jsonl, validation.jsonl, and full.jsonl.2
Upload Dataset to Hugging Face
Ensure you are logged in to your environment with the Hugging Face CLI.
Make sure you have
huggingface_hub installed using pip and you have logged in using the following command:Uploading Prem Fine-Tuned Models to Hugging Face
Prem Studio offers both Reasoning and Non-Reasoning fine-tuning. In Non-Reasoning fine-tuning, there are two fine-tuning methods: LoRA and Full fine-tuning. If you don’t know what LoRA is, you can check that out here quickly. Here are some key differences:- LoRA fine-tuning downloads only the additional adapter weights that were trained on top of the base model. They are available with both reasoning and non-reasoning fine-tuning.
- Full fine-tuning downloads the complete model with all updated parameters. Note that these can be very large files. They are available only for non-reasoning fine-tuning.
In this guide, we’ll show you how to upload model checkpoints fine-tuned using both LoRA and full fine-tuning methods.
Uploading LoRA Fine-Tuned Models to Hugging Face
LoRA (Low-Rank Adaptation) creates lightweight adapter files that work with a base model. When uploading LoRA models, you’re essentially uploading these adapter weights that can be loaded on top of the original base model. Here’s how to upload your LoRA fine-tuned model:When uploading LoRA checkpoints, you’ll need the 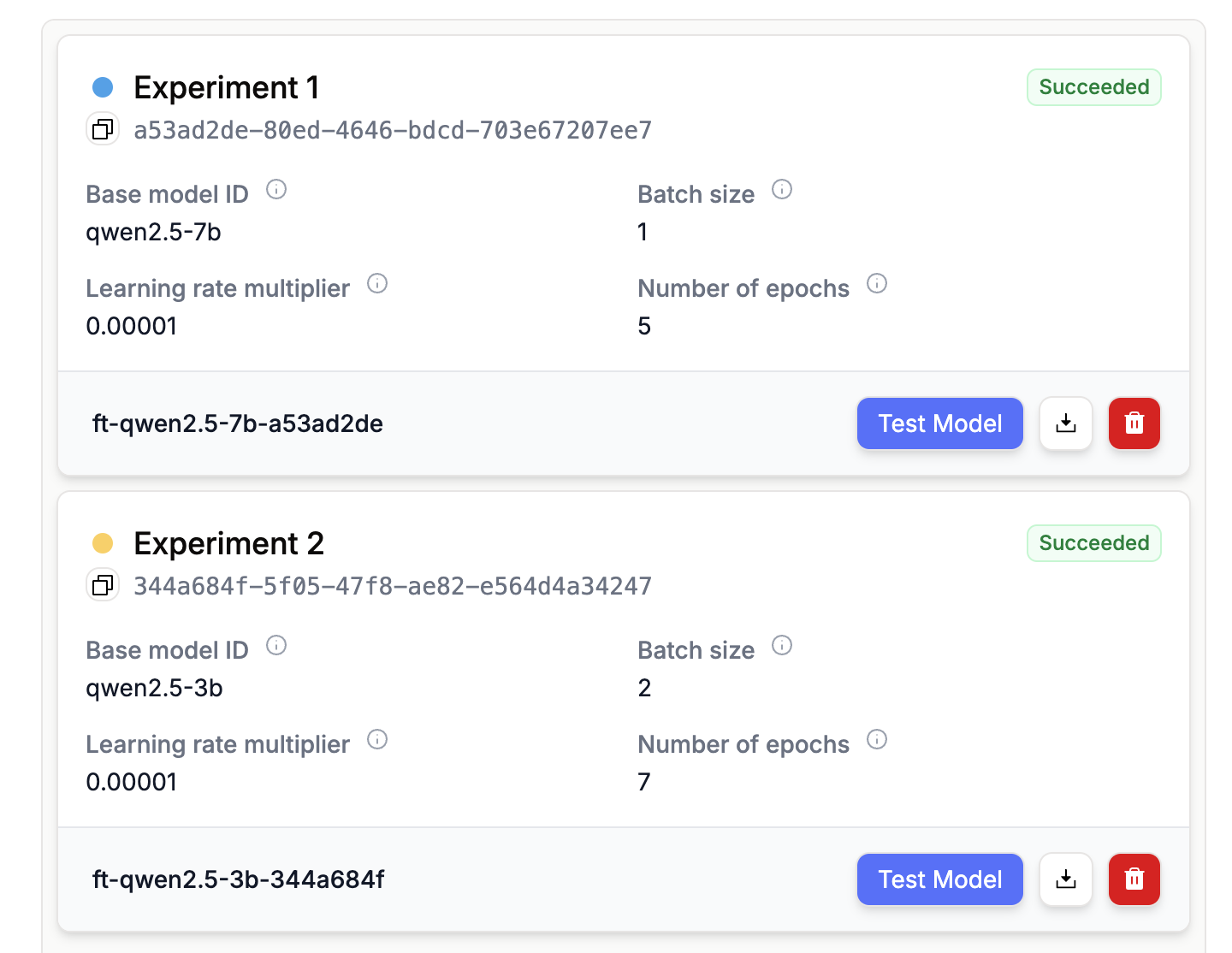
base_model_id from Hugging Face that corresponds to the model you fine-tuned. You can find the base model name in your fine-tuning page, then use the table below to get the correct Hugging Face model ID.| Model Name | Hugging Face Model ID |
|---|---|
| llama3.2-1b | meta-llama/Llama-3.2-1B |
| llama3.2-3b | meta-llama/Llama-3.2-3B |
| llama3.1-8b | meta-llama/Llama-3.1-8B |
| qwen2.5-0.5b | Qwen/Qwen2.5-0.5B |
| qwen2.5-1.5b | Qwen/Qwen2.5-1.5B |
| qwen2.5-3b | Qwen/Qwen2.5-3B |
| qwen2.5-7b | Qwen/Qwen2.5-7B |
| gemma3-1b | google/gemma-3-1b-it |
| gemma3-4b | google/gemma-3-4b-it |
| smolllm-135m | HuggingFaceTB/SmolLM-135M |
| smolllm-360m | HuggingFaceTB/SmolLM-360M |
| smolllm-1.7b | HuggingFaceTB/SmolLM-1.7B |
| phi-3.5-mini | microsoft/Phi-3.5-mini-instruct |
| phi-4-mini | microsoft/Phi-4-mini-instruct |
| qwen2.5-math-1.5b | Qwen/Qwen2.5-Math-1.5B |
| qwen2.5-math-7b | Qwen/Qwen2.5-Math-7B |
Uploading Full Fine-Tuned Models to Hugging Face
Full fine-tuning creates a complete model with all parameters updated for your specific task. This approach gives you maximum flexibility but results in larger file sizes. Here’s how to upload your full fine-tuned model:What Happens After Upload?
Once your datasets or models are uploaded to Hugging Face, they become part of the Hugging Face ecosystem. This means:- Easy sharing: Your datasets and models can be easily shared with colleagues or the community
- Version control: Hugging Face automatically handles versioning of your uploads
- Integration: Your models can be used with popular ML frameworks like Transformers, Datasets, and more
- Discoverability: Public repositories can be discovered by the ML community
Remember to set appropriate visibility (private or public) for your repositories based on your needs. You can always change this later in your Hugging Face repository settings.