

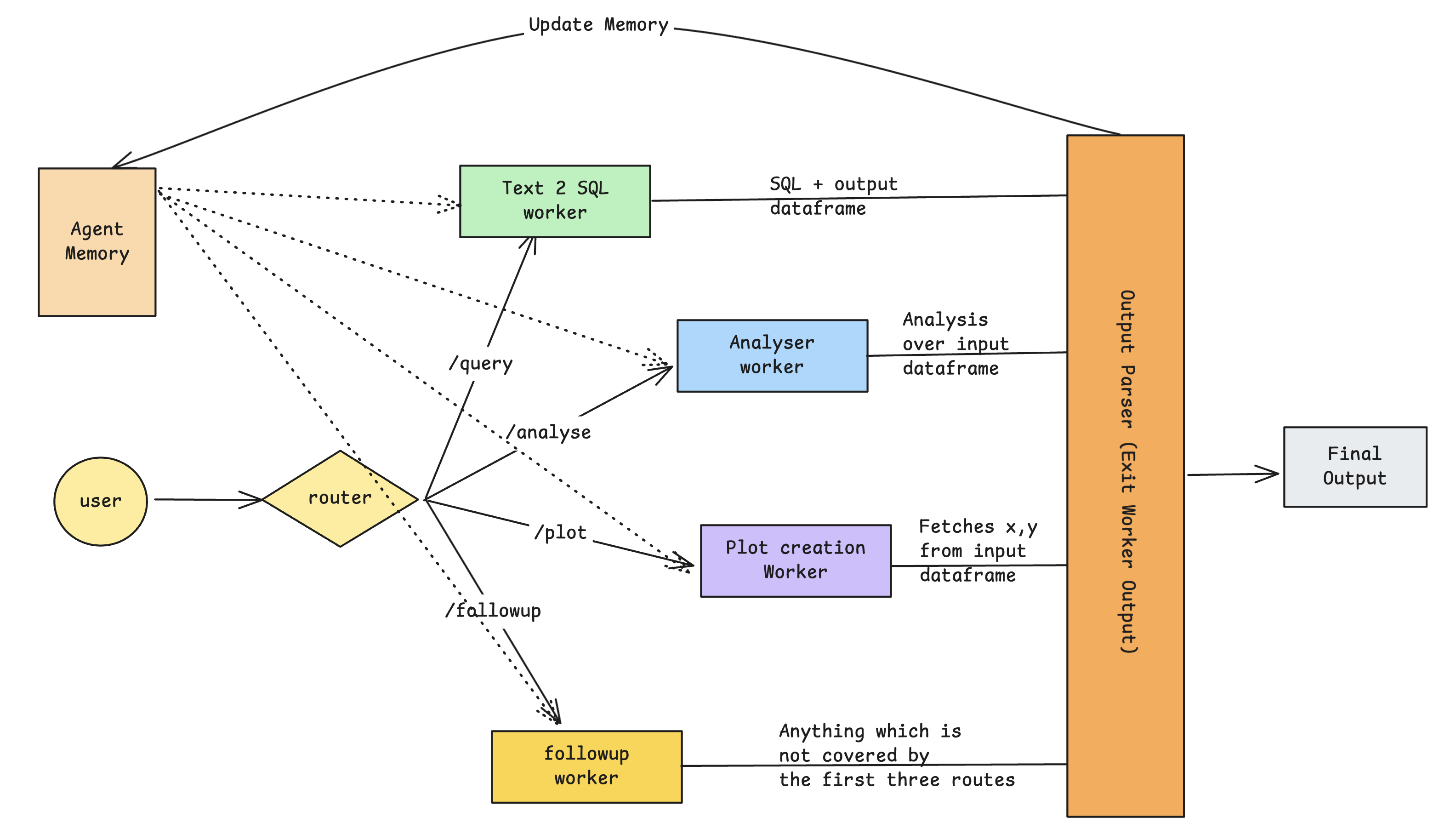
- Query to a database from user’s natural language input.
- Analyse the database output and user query and give back a answer in natural language.
- Plot basic charts based on user’s query.
- Lastly anything which does not fit the above three categories, it can give you a followup on what do next.
/query: This will tell agent to go, write a SQL query and execute to the DataBase./analyse: This will analyse the dataframe and based on user’s query will give an concise natural language answer./plot: This will plot basic charts / graphs from the output dataframes and user’s input query./followup: If the user do not start with the above three markers or when the wokers (LLM / SLM) of the agent fails then it goes into this route. Here the worker tells what to do next.
Prerequisites
Before diving in, ensure you have a basic understanding of the following premsql components:Generators Tutorial
A step-by-step guide on how to use Text-to-SQL generators to create SQL queries from user input and specified database sources.
Executors Tutorial
Learn how to connect to databases and execute SQL queries generated by models. This tutorial covers execution, troubleshooting, and best practices.
Terminologies
Before proceeding, we discuss some terminology conventions we use for PremSQL Agents.- Agent: An agent is considered to be the complete overall workflow.
- Workers: Workers are the LLMs / SLMs which is instructed / designed to do some task.
- Tools: Tools are the deterministic / programmable functions (which does not contain models in general) that helps the worker either to provide contexts or helps to execute some task.
baseline agent. In other words, Baseline means the minimal agentic implementation that can do all the following tasks. However using the premsql library you can make task specific Database RAG agents or extend the existing ones.
BaseLine Agent
PremSQL comes with a minimal agentic implementation (more implementation variants will come in later versions), which can query to a DB, provide analysis over dataframes and answer user questions and plot simple graphs. This is how you use our baseline Text to SQL agent.- Prem-1B-SQL: This is a 1.3B parameter model, fully fine-tuned from DeepSeek coder 1.3B specialized to perform Text to SQL tasks. This will be used for our text to SQL worker.
-
LLama-3.2-1B: For all the other tasks:
analyse/plotandfollowup, we are going to use this model.
Text2SQLGeneratorHF / Text2SQLGeneratorOpenAI or Text2SQLGeneratorPremAI / Text2SQLGeneratorOllama to use other open or closed source models as well. Now, let’s proceed with instantiating our BaseLine agent.
-
session_name: A string identifier for the current session, likely used for tracking or logging purposes. -
db_connection_uri: A string containing the database connection URI that specifies how to connect to the database. -
specialized_model1: A Text2SQL model instance used primarily for SQL generation tasks. Based on the code, this is used in the text2sql_worker. -
specialized_model2: A second Text2SQL model instance used for analysis, plotting, and followup tasks. This model is shared among multiple workers. -
executor: An instance of BaseExecutor that handles the execution of SQL queries against the database. -
plot_tool: An instance of BasePlotTool that provides plotting capabilities for data visualization.
-
session_db_path: An optional string parameter specifying the path to store session-related data. -
include_tables: An optional list of tables to include in the database operations, used for filtering available tables. -
exclude_tables: An optional list of tables to exclude from database operations, used for filtering available tables. -
auto_filter_tables: An optional boolean flag that likely controls automatic table filtering behavior. -
route_worker_kwargs: An optional dictionary containing additional keyword arguments for different worker routes (query, analyse, plot, etc.).
Note about route_worker_kwargs
Note about route_worker_kwargs
The What’s happening here?
route_worker_kwargs parameter lets you customize how different parts of the agent behave. Think of it as a control panel for fine-tuning each worker’s settings.Here’s a simple example:-
For analysis tasks (
/analyse):- Breaks down large datasets into chunks of 40 rows for better handling
- Uses a slightly higher temperature (0.18) to allow for more creative analysis
- Allows longer responses (600 tokens) since analysis often needs more explanation
-
For SQL queries (
/query):- Uses a lower temperature (0.1) to keep SQL generation precise and consistent
- Limits response length (256 tokens) since SQL queries are typically shorter
Running BaseLine agent
Here is simply how you can run the agent: For Querying to Database/query route. It searches for the latest output
and feed that as the input and then provide the analysis.
For plotting charts
/query route. It searches for the latest output
and feed that as the input and then go for selecting the columns of the latest input/output dataframe and selects which columns and which plot type needs to be chosen from user’s input. Current supported plot types are: scatter, line, area, histogram and bar plot.
Everything else followup route
Modes of Agent run
There are three modes in which your agent can run. One way to run these agent is using this line of code:ExitWorkerOutput meaning, when one conversation cycle finishes it accumulates all the information and outputs it in a structural format. Here are all the information ExitWorkerOutput provides you:
server_mode to be on while calling the agent which looks like this:
AgentOutput Which is a less granular form of ExitWorkerOutput which contains
the following attributes:
Please Note
When you call an agent like this:
agent(...), for routes like /analyse and /plot then it assumes that it would do
the analysis on the latest output dataframe which was output from /query plot. So suppose if you want an analysis from
what how are the main topics of the comments table. Then you need to previously query the agent to output some dataframe that
has the comments information.Workers inside Baseline
You can either use the BaseLine agent to run your things or you can also use each of the workers independently. Inside BaseLine there are mainly three workers as follows:- Text to SQL Worker: This worker gets invoked when we start anything with
/query. - Analysis Worker: This worker gets invoked when we start anything with
/analyse. - Plot Worker: This worker gets invoked when we start anything with
plot.
Text to SQL Worker
The task of Text to SQL worker is pretty much self explanatory. This worker inside BaseLine agent get’s invoked when we write anything starting with/query. However if you use this worker independently then there is no need to do that. Here is how we define the Text to SQL worker inside BaseLine agent.
db_connection_uri (str): Database connection string to connect to the target database.generator (Text2SQLGeneratorBase): Main model for generating SQL queries from text.helper_model (Optional[Text2SQLGeneratorBase]): Secondary model for table filtering and error correction. Defaults to None.executor (Optional[BaseExecutor]): Custom executor for running SQL queries. If None, uses default.include_tables (Optional[list]): List of tables to specifically include in schema context. If None, includes all tables.exclude_tables (Optional[list]): List of tables to exclude from schema context. If None, no tables are excluded.auto_filter_tables (Optional[bool]): Whether to automatically filter relevant tables for each query. Defaults to False. This will call the model one more time and it is recommended to use when model is strong and you have very large number of schemas.
question (str): The natural language query to be converted to SQLadditional_knowledge (Optional[str]): Extra context or information to help with query generationfewshot_dict (Optional[dict]): Dictionary of example question-SQL pairs for few-shot learningtemperature (Optional[float]): Controls randomness in SQL generation (0.0 = deterministic, 1.0 = most random)max_new_tokens (Optional[int]): Maximum number of tokens to generate in the SQL queryrender_results_using (Optional[Literal["json", "dataframe"]]): Output format for query resultsprompt_template (Optional[str]): Custom template for the main SQL generation prompterror_handling_prompt_template (Optional[str]): Custom template for error correction prompts
Analyser Worker
The Analyser Worker is responsible for analyzing data and providing insights from dataframes. In the BaseLine agent, this worker is invoked when queries start with/analyse. Here’s how to initialize the Analyser Worker:
generator (Text2SQLGeneratorBase): Model used for generating analysis from the data.
question (str): The natural language question about what to analyze in the datainput_dataframe (pd.DataFrame): The dataframe to analyzedo_chunkwise_analysis (Optional[bool]): Whether to break analysis into chunks for large datasets. Defaults to Falsechunk_size (Optional[int]): Number of rows per chunk when doing chunkwise analysis. Defaults to 20max_chunks (Optional[int]): Maximum number of chunks to analyze. Defaults to 20temperature (Optional[float]): Controls randomness in analysis generation (0.0 = deterministic). Defaults to 0.19max_new_tokens (Optional[int]): Maximum number of tokens to generate in the analysis. Defaults to 600analysis_prompt_template (Optional[str]): Custom template for the main analysis promptanalysis_merger_template (Optional[str]): Custom template for merging chunk analysesverbose (Optional[bool]): Whether to print detailed progress. Defaults to False
Chunked Analysis
For large datasets, the worker can break the analysis into chunks usingdo_chunkwise_analysis=True. This process:
- Splits the input dataframe into chunks of size
chunk_size - Analyzes each chunk separately
- Combines the chunk analyses using a merger prompt
- Returns a consolidated analysis
Chart Plot Worker
The Chart Plot Worker is responsible for generating visualization configurations and plotting data based on natural language queries. In the BaseLine agent, this worker is triggered when queries start with/plot. However, it can be used independently without this prefix. Here’s how to initialize the Chart Plot Worker in the BaseLine agent:
generator (Text2SQLGeneratorBase): Model for generating plot configurations from textplot_tool (BasePlotTool): Tool for creating and rendering plots (e.g., PlotlyTool)
question (str): Natural language description of the desired visualizationinput_dataframe (pd.DataFrame): Data to be plottedtemperature (Optional[float]): Controls randomness in configuration generation (default: 0.1)max_new_tokens (Optional[int]): Maximum tokens for configuration generation (default: 100)plot_image (Optional[bool]): Whether to generate base64 image of plot (default: True)prompt_template (Optional[str]): Custom template for plot configuration generation
Current State and Future Roadmap
PremSQL is actively evolving, with a strong foundation in reliable output generation and structured error handling. Here are some areas we’re currently working on to make PremSQL even better:-
Memory and Context Management
- Current Implementation: Uses an efficient SQLite-based system for conversation tracking, with smart truncation for large datasets (first 200 rows) to maintain performance
- Future Enhancement: Planning to add semantic search capabilities to enable more intelligent context retrieval and cross-reference previous conversations
-
Visualization Capabilities
- Current Implementation: Supports essential chart types with reliable rendering for common data visualization needs
- Future Enhancement: Expanding to support more complex visualizations and comparative analysis features
-
Retrieval and Search
- Current Implementation: Direct and efficient table/data access
- Future Enhancement: Integration with vector databases to enable more sophisticated semantic search and context understanding