

🧠 Why This Matters
Good models start with good data. Whether you’re fine-tuning, evaluating, or experimenting, following a few simple best practices can make a big difference. This guide helps you:- Avoid common mistakes in dataset preparation.
- Set up reliable validation processes.
- Understand how much data is enough.
- Use your synthetic data effectively — without biasing your results.
✅ Key Best Practices
Always Have a Validation Dataset
A validation dataset is essential if you want to measure model quality.
- Use it during fine-tuning to quickly monitor the model performance.
- Use it to benchmark different models with our agentic evaluator.
If you’re not using a validation dataset, you won’t be able to run evaluations in Prem Studio.
Avoid Using Synthetic Data for Validation
Synthetic data is great for training, but avoid using it for validation:
- It can inflate performance metrics.
- It might not capture the full complexity of real-world inputs.
How Much Data Do You Actually Need?
The amount of data you need depends on the complexity of your task. Text classification or simple QA tasks may require fewer examples, while nuanced or open-ended tasks typically need more.As a rule of thumb:After initial fine-tuning, you can assess whether more data is needed by:
- Start with a few hundred training examples to test your setup.
- Start with a few dozens validation examples.
Having too few validation examples can lead to noisy evaluation results — both during fine-tuning (unreliable loss function) and during agentic evaluation, where a small sample may be insufficient to draw meaningful conclusions.
- Reviewing the training loss curve.
- Running evaluations on your validation set.
- Checking performance with agentic evaluation tools in Prem Studio.
📦 What’s Next?
Now that your dataset follows these practices, you’re ready to:- Fine-tune a model using Prem Studio Fine-Tuning
- Run robust evaluations with your validation set (Evaluation Guide)
- Enrich your dataset if needed (Enrichment Guide)
💡 Pro Tips
- Name your dataset clearly to reflect its purpose or use case.
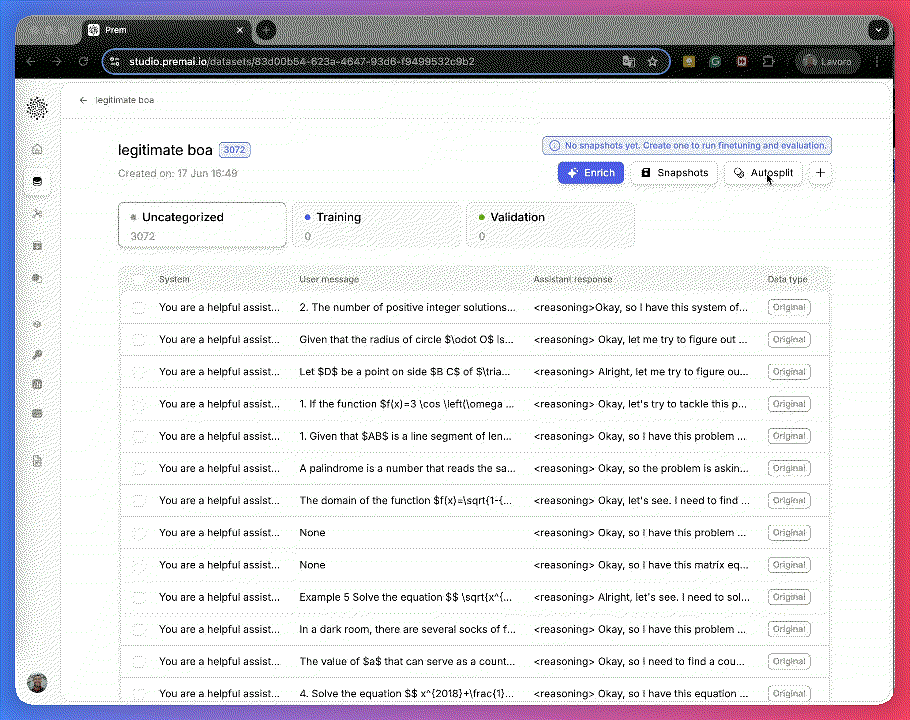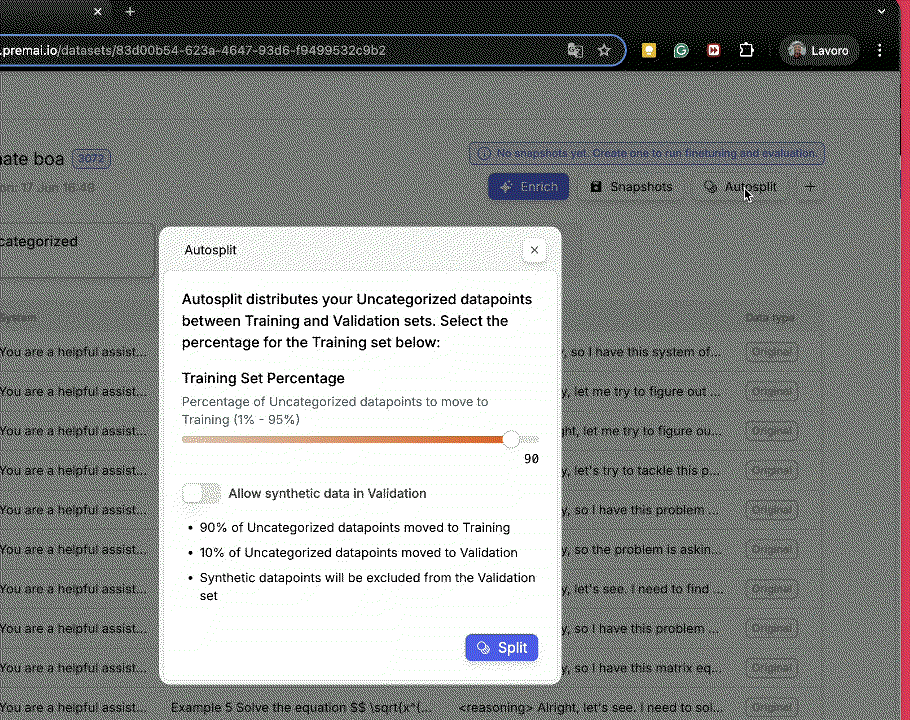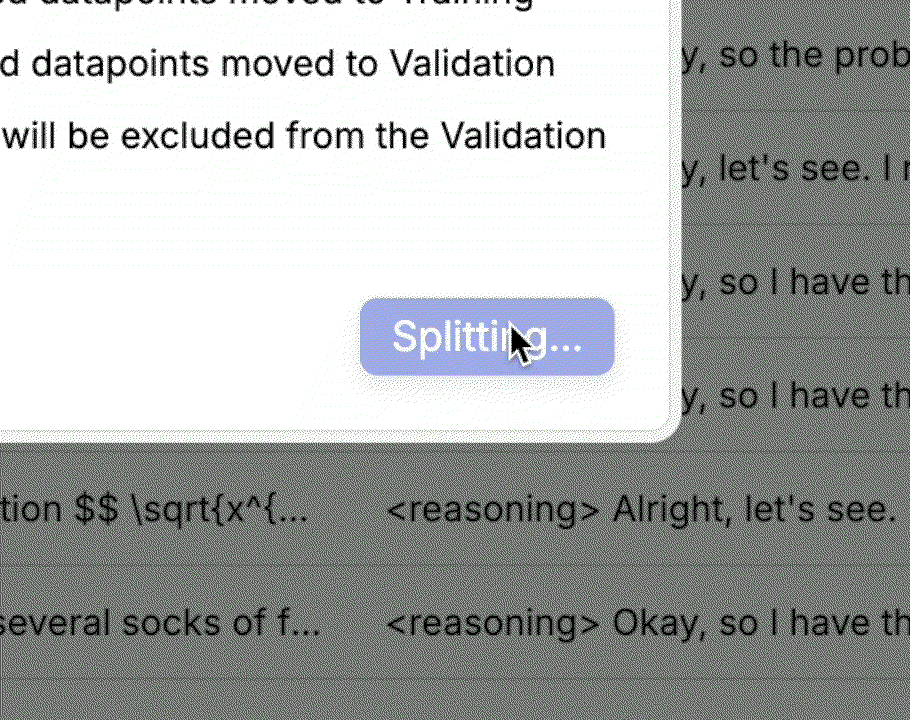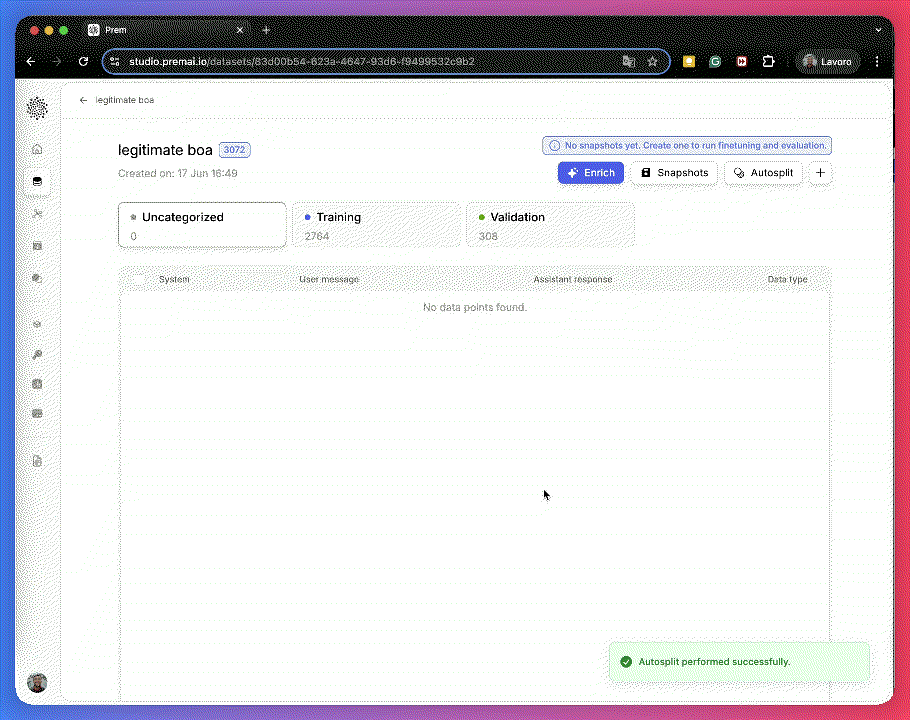
- Use autosplit for quick, clean train/validaiton separation.
- Periodically re-check your validation set to make sure it reflects real-world data.