

🧠 Why This Matters
Creating high-quality QA datasets is often a bottleneck. With synthetic QA generation, you can:- Convert any text source into structured QA pairs.
- Quickly scale your dataset with minimal manual effort.
- Prepare reliable data for fine-tuning or evaluating small and large language models (SLMs/LLMs).
Example use case - Structured Output from Receipts In this guide we will see how to synthetically generate QA pairs from a set of receipts. We’ll use 20 invoice receipts from this dataset. Each file will generate 1 Synthetic QA pair, producing a structured JSON output that extracts key fields (date, total amount, business name, etc.). This type of dataset is crucial for fine-tuning models that need to reliably extract structured data from semi-structured sources (like receipts, tickets, or invoices).
⚙️ Step-by-Step: Using QA Generation in Prem Studio
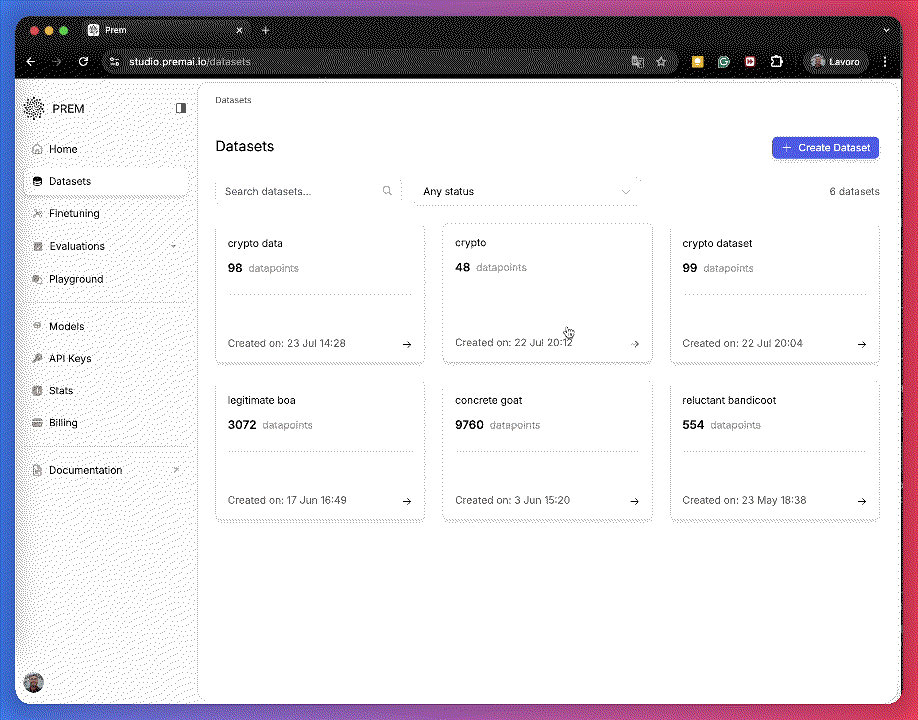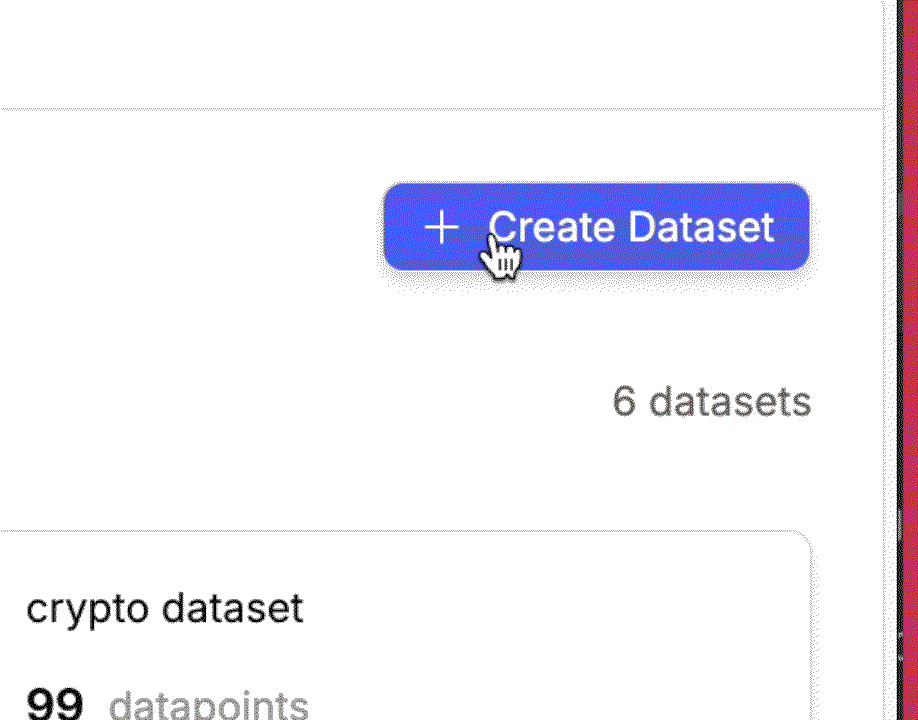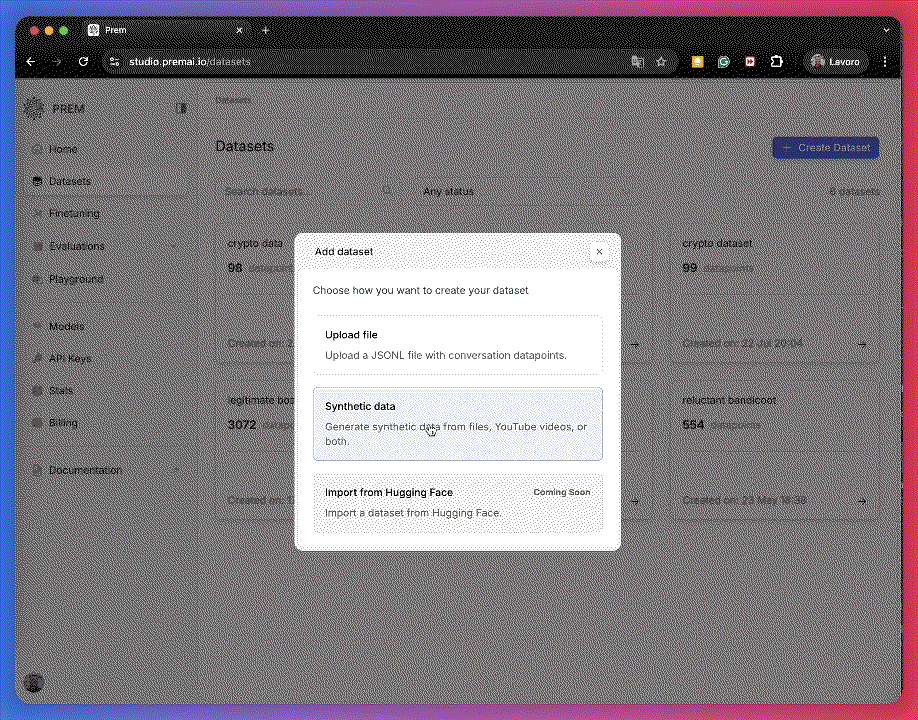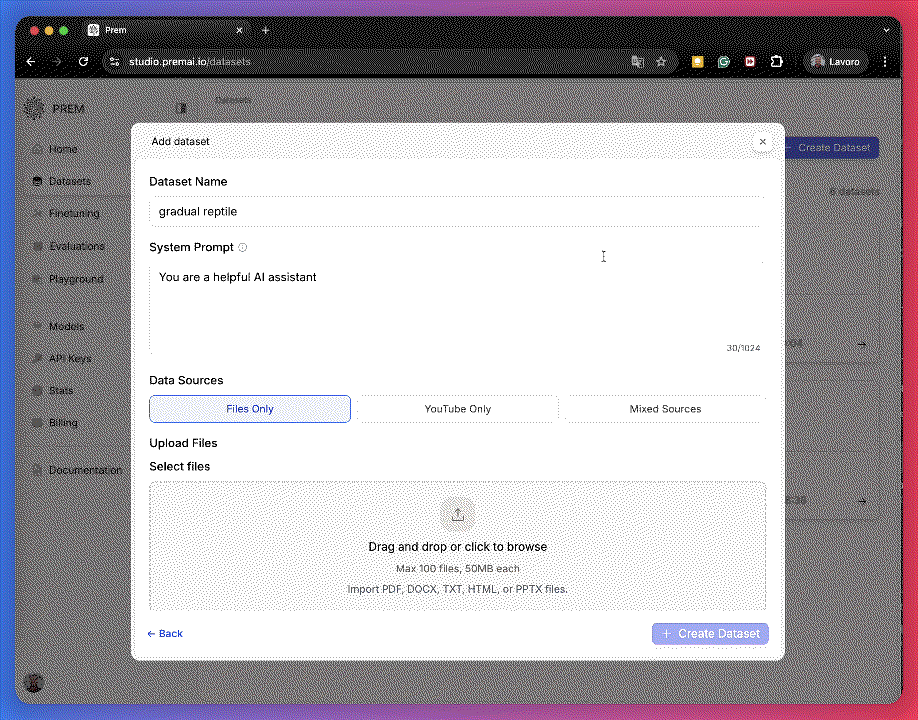
Upload Your Input Files
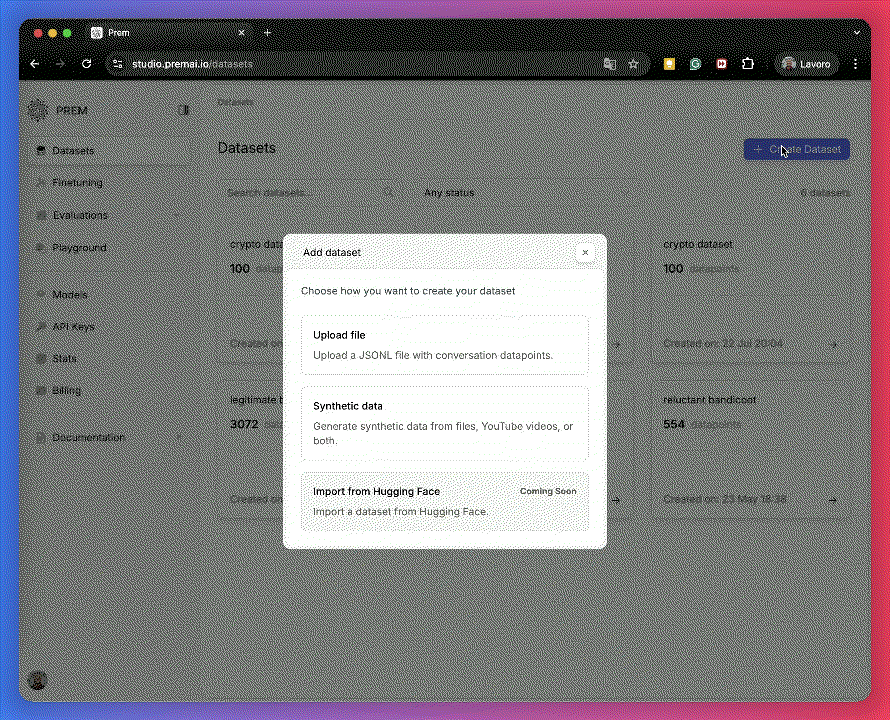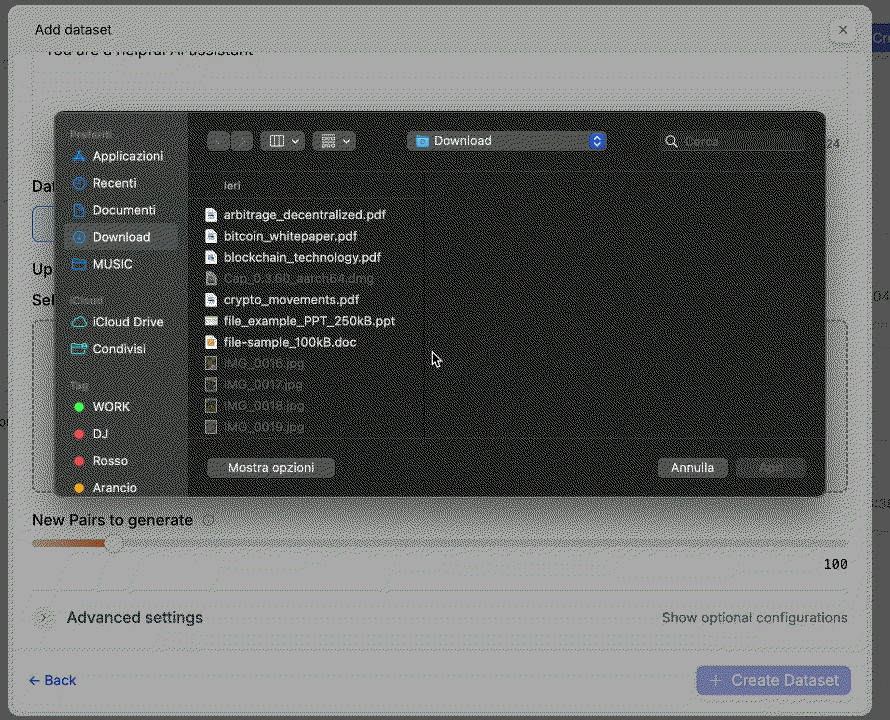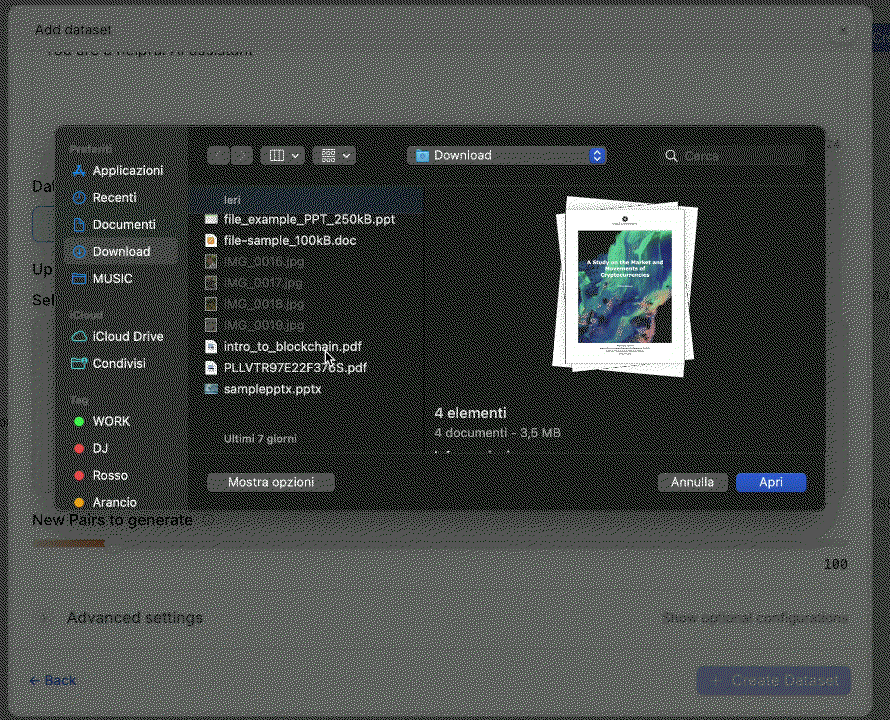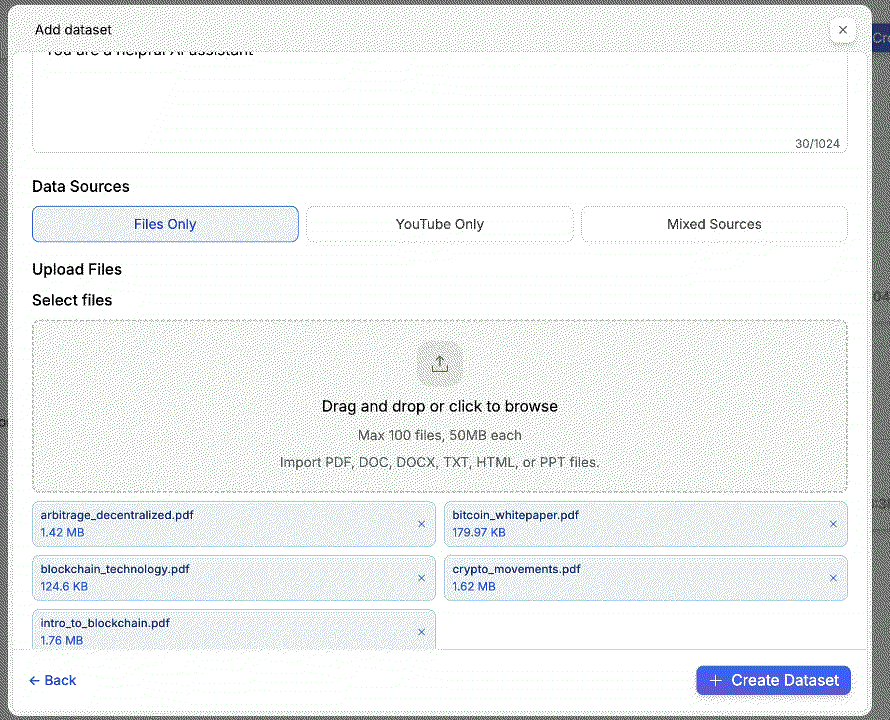 Drag and drop your text files (PDF, DOCX, TXT, HTML).
📌 In this example, we use 20 invoice receipts.
Drag and drop your text files (PDF, DOCX, TXT, HTML).
📌 In this example, we use 20 invoice receipts.Configure Advanced Settings (Optional but Recommended)
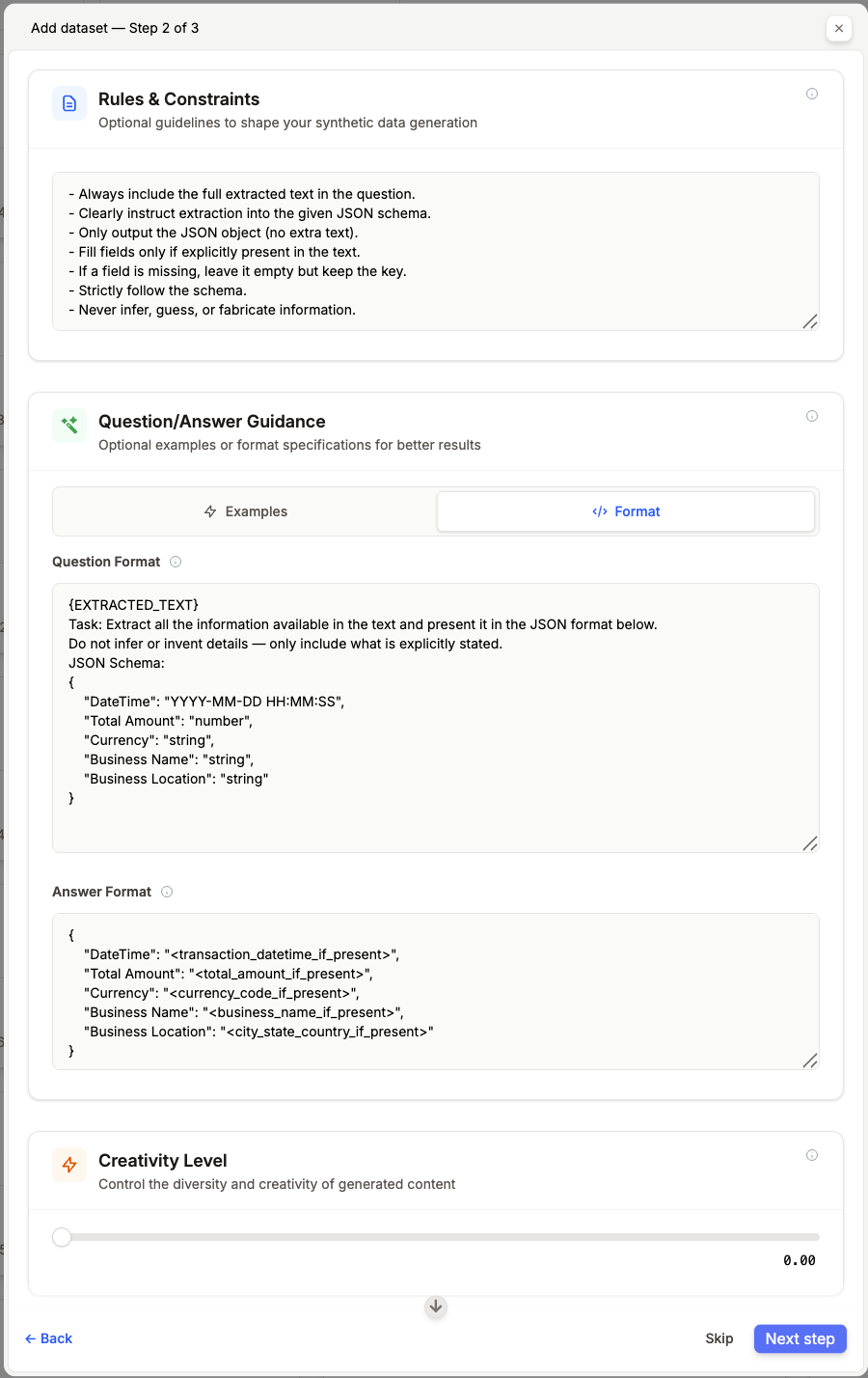 This step lets you steer the QA generation toward your expected output. It includes:
This step lets you steer the QA generation toward your expected output. It includes:- Rules & Constraints → enforce requirements.
- QA Examples (up to 3) → provide few-shot examples to guide generation.
- Question/Answer Guidance → define QA formats.
- Creativity Level → adjust diversity of generated QAs.
4. Review & Generate
Before starting, you’ll see a recap of your setup: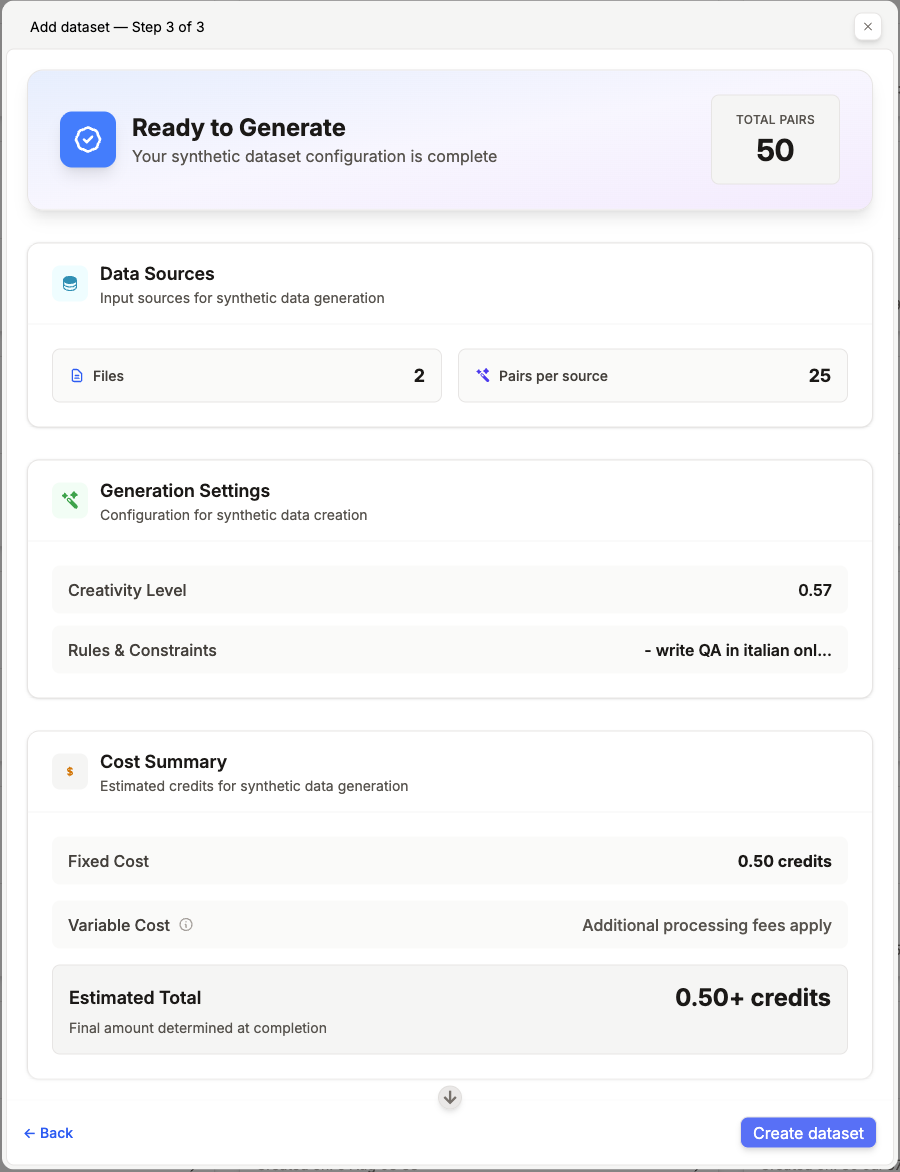
- Data sources (your input files).
- Generation settings (QA per file, creativity level, etc.).
- Estimated cost. Click Create dataset to start the process.
📦 What’s Next?
You can now:- Preview and edit the generated data
- Fine-tune your model with it (see our fine-tuning guide)
- Evaluate models against it (see our evaluation guide)
💡 Pro Tips
- Always define advanced settings if you expect strict outputs.
- Start small (10–20 docs) to validate your setup, then scale up.
- Use domain-specific schemas (invoices, medical records, support tickets, etc.).
- Keep creativity low when extracting structured data.