

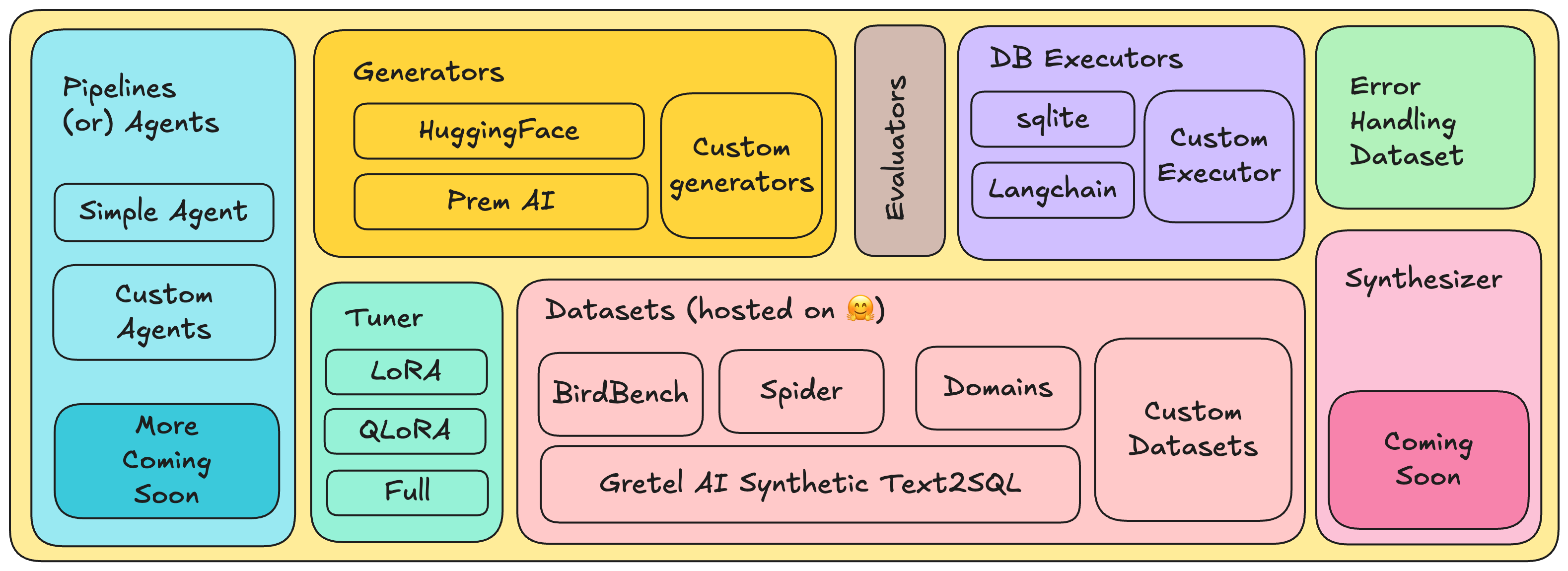
Core Components
PremSQL GitHub
Star the project to stay updated with our rapid development of the best local Text-to-SQL solution.
News
- [Sep 10th 2024] Initial release of PremSQL
- [Sep 10th 2024] Launch of Prem-1B-SQL (fully local Text to SQL model)
- [Oct 30th 2024] Prem-1B-SQL surpassed 5K+ downloads
- [Nov 5th 2024] Release of PremSQL Playground, Agents, and AgentServer
- [Nov 10th 2024] Release of Prem-1B-SQL Ollama model with Ollama support
Installation
Start by creating a virtual environment and installing PremSQL:Note: We currently recommend using Python virtualenv instead of conda, as some users have reported compatibility issues with conda environments.
Note
The latest PremSQL update doesn’t include pre-installed dependencies to accommodate backend variations and maintain a lighter package. Choose your preferred backend:For Hugging Face Transformers:For Apple MLX backend:For Ollama integration, first install Ollama, then install the Python client:
- Use PremSQL’s pre-built Agent UI with our baseline agent to analyze CSVs, databases, or Kaggle datasets (as demonstrated in the demo video)
- Leverage PremSQL as a Python library to:
- Run the PremSQL backend API server and integrate it with your preferred programming language
Quick Start
Let’s explore how to use PremSQL’s latest baseline agent with Ollama. We’ve chosen Ollama for this guide because it’s easy to set up, requires minimal computational resources, and runs everything locally at no cost. However, you can also use Apple MLX, Hugging Face Transformers, or other supported backends.1
PremSQL installation with Ollama and model downloads
First, ensure PremSQL is installed with the Ollama client. If you haven’t done so, follow the installation instructions above. We’ll use two models:
Prem-1B-SQL and Llama3.2 1B. Download both models using these commands:Optional optimization
Optional optimization
By default, Ollama runs one model at a time. To optimize PremSQL agent performance with multiple models, configure these environment variables:Remember to restart Ollama after making these changes.
2
Launch PremSQL Server and Agent UI
PremSQL includes a CLI tool for managing the backend API server and Agent UI. Running This confirms that PremSQL is installed correctly. Verify you have version On first run, it will execute database migrations before starting the server and Streamlit agent UI. A successful launch looks like this:
premsql in your terminal displays:0.1.11 or higher. Launch both the backend API server and playground with:linux, windows and mac
3
Import a dataset from Kaggle
To import a Kaggle dataset into PremSQL, ensure it contains only CSV files (multiple files are supported). Simply copy the dataset ID (in this case, 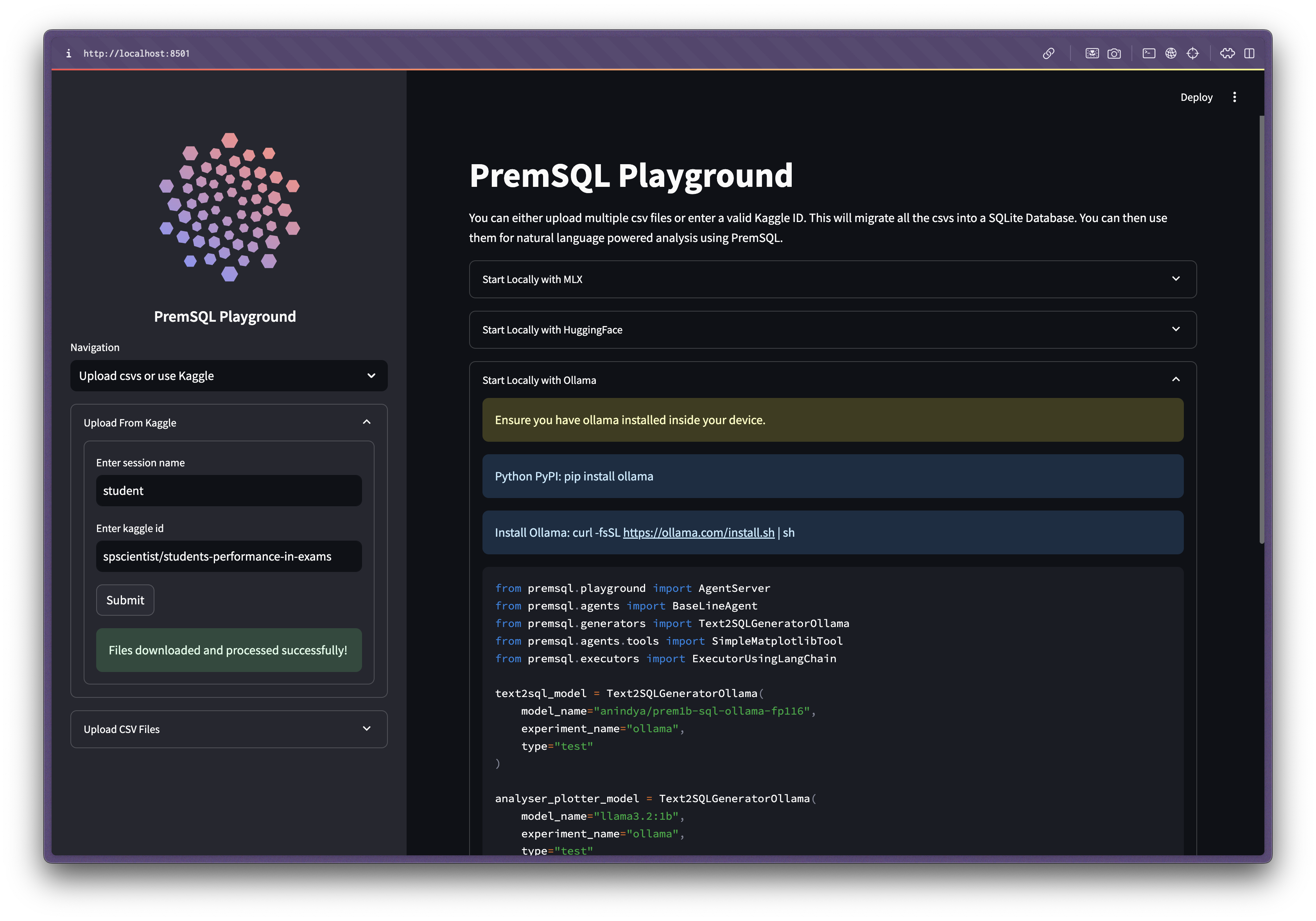
spscientist/students-performance-in-exams) and paste it into the Upload csvs or use Kaggle field in the PremSQL navigation. After submission, you’ll see:4
Start a PremSQL analysis session
For this demo, we’ll use the Ollama starter code. Create a new file anywhere and add this code:Run this code in your terminal within your PremSQL environment:You should see FastAPI server output similar to:This confirms that PremSQL is installed correctly. Verify you have version On first run, it will execute database migrations before starting the server and Streamlit agent UI. A successful launch looks like this:
starter_server.py
0.1.11 or higher. Launch both the backend API server and playground with:linux, windows and mac
5
Import a dataset from Kaggle
To import a Kaggle dataset into PremSQL, ensure it contains only CSV files (multiple files are supported). Simply copy the dataset ID (in this case,
spscientist/students-performance-in-exams) and paste it into the Upload csvs or use Kaggle field in the PremSQL navigation. After submission, you’ll see:6
Start a PremSQL analysis session
For this demo, we’ll use the Ollama starter code. Create a new file anywhere and add this code:Run this code in your terminal within your PremSQL environment:You should see FastAPI server output similar to:Copy the localhost URL (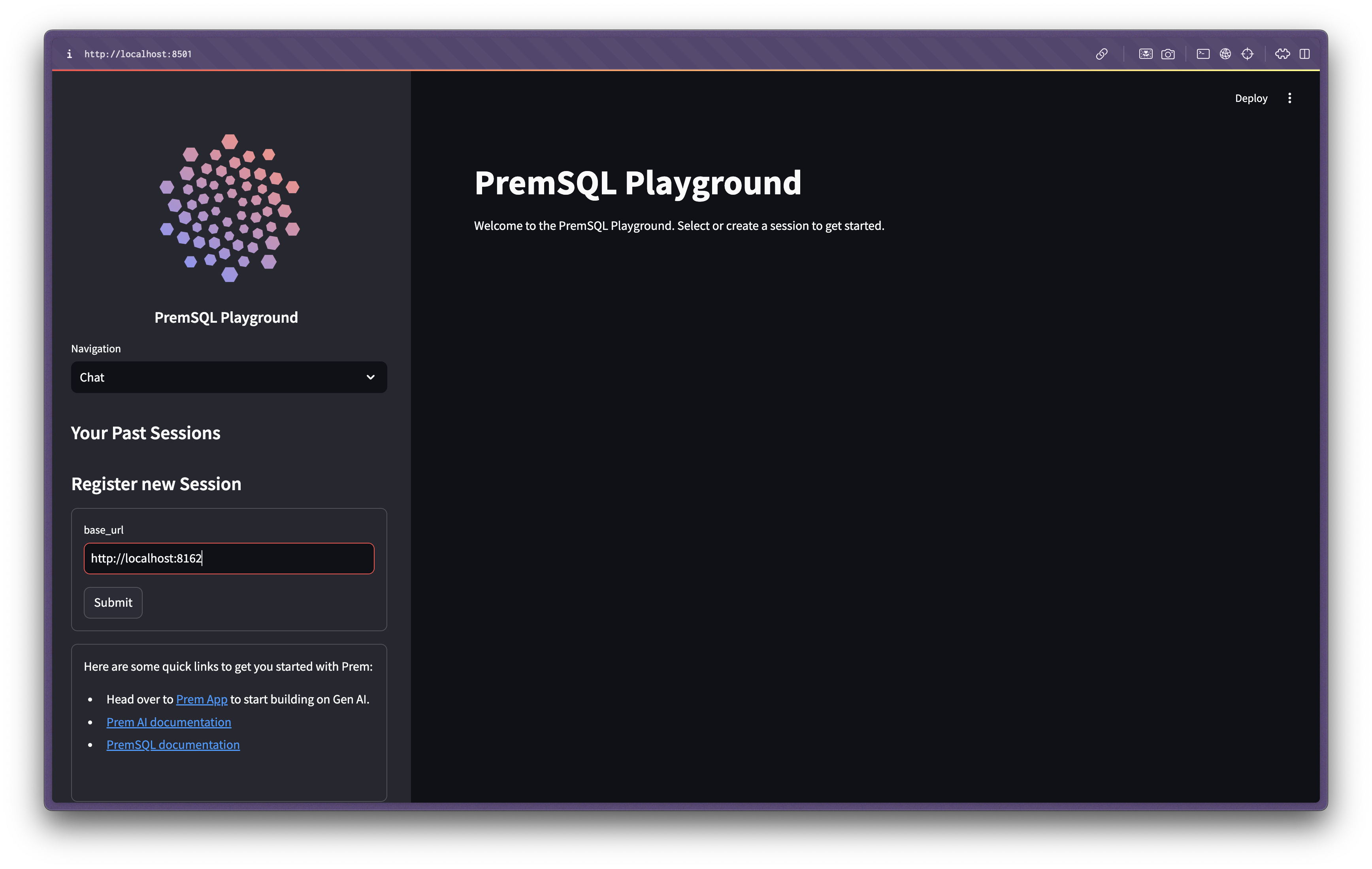
starter_server.py
http://localhost:8162) and paste it here:Note
This is a starter implementation using our baseline agent. You can create custom agents with different functionalities (within data analysis scope) by extending this code. The snippet above demonstrates our baseline implementation for Autonomous Analysis agents.
7
You’re all set! You can now perform analysis on various data sources like CSVs, Databases and Kaggle csv datasets.
PremSQL Datasets
Pre-processed datasets hosted on HuggingFace for Text-to-SQL tasks. Ideal for evaluation, fine-tuning, and creating custom datasets.
PremSQL Generators
Models that transform natural language input into SQL queries based on your database schema.
PremSQL Executors
Connects to databases and executes generated SQL queries to fetch results.
PremSQL Evaluators
Evaluates Text-to-SQL models using metrics like execution accuracy and Valid Efficiency Score (VES).
PremSQL Error Handling
Creates error handling prompts and datasets to enhance inference reliability and self-correction capabilities.
PremSQL Tuner
Fine-tunes open-source models on Text-to-SQL datasets with custom evaluation methods for optimal performance.
PremSQL Agents
End-to-end agentic workflows for querying, analyzing, and visualizing database insights using natural language. Supports custom implementations for specialized use cases.
PremSQL Playground
A ChatGPT-like interface specialized for database interactions. Deploy PremSQL agents with customized configurations for an interactive experience.
Why PremSQL? The Vision
PremSQL is focused on creating local Text-to-SQL workflows. In many scenarios, organizations need to maintain data privacy while leveraging generative AI solutions for productivity and innovation. PremSQL addresses this need by keeping your data entirely local. Key Use Cases:- Interactive database querying and analysis
- RAG systems with database integration
- Intelligent SQL autocompletion
- Self-hosted AI-powered data analysis
- Autonomous agentic pipelines with secure database access