

Data Collection and Preparation
For this example, we use this invoice dataset that instructs the LLM to extract important information from invoices based on user prompts. Here’s a sample from our dataset: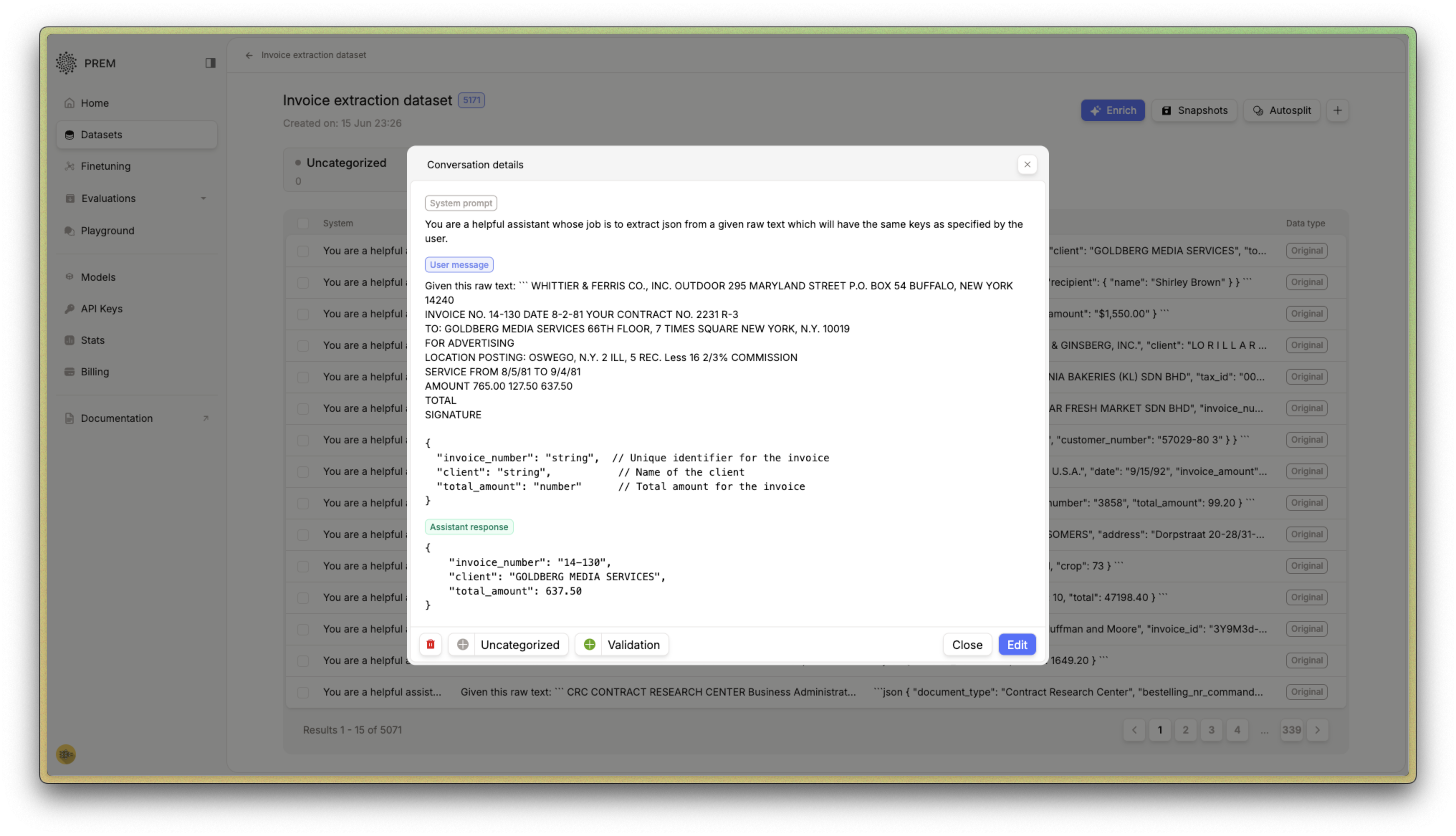
If you’re new to working with datasets in Prem Studio, check out our dataset getting started guide to learn the fundamentals of dataset management.
Fine-Tuning the Model
With our dataset snapshot ready, we navigate to the fine-tuning section and create a new fine-tuning job: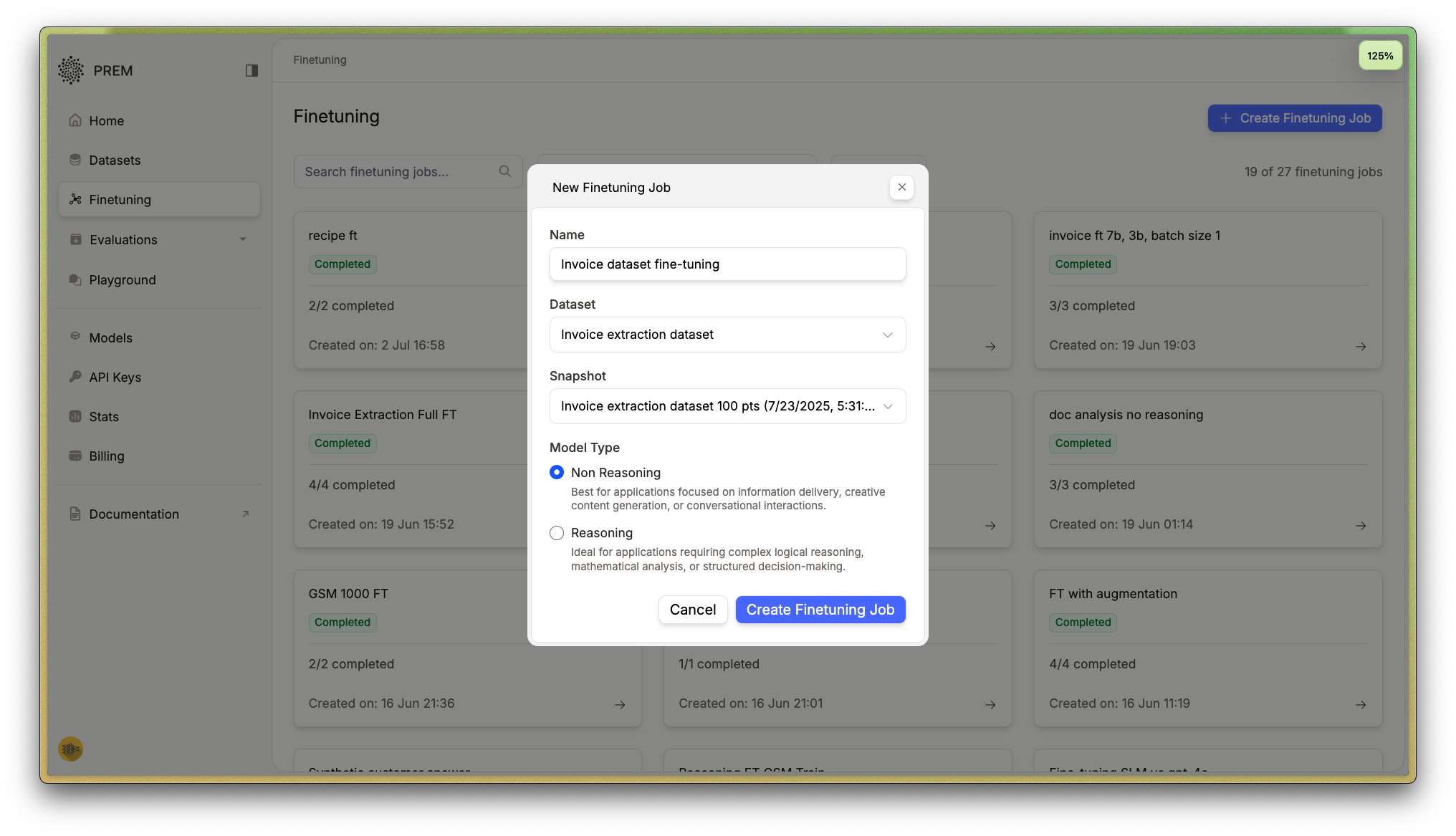
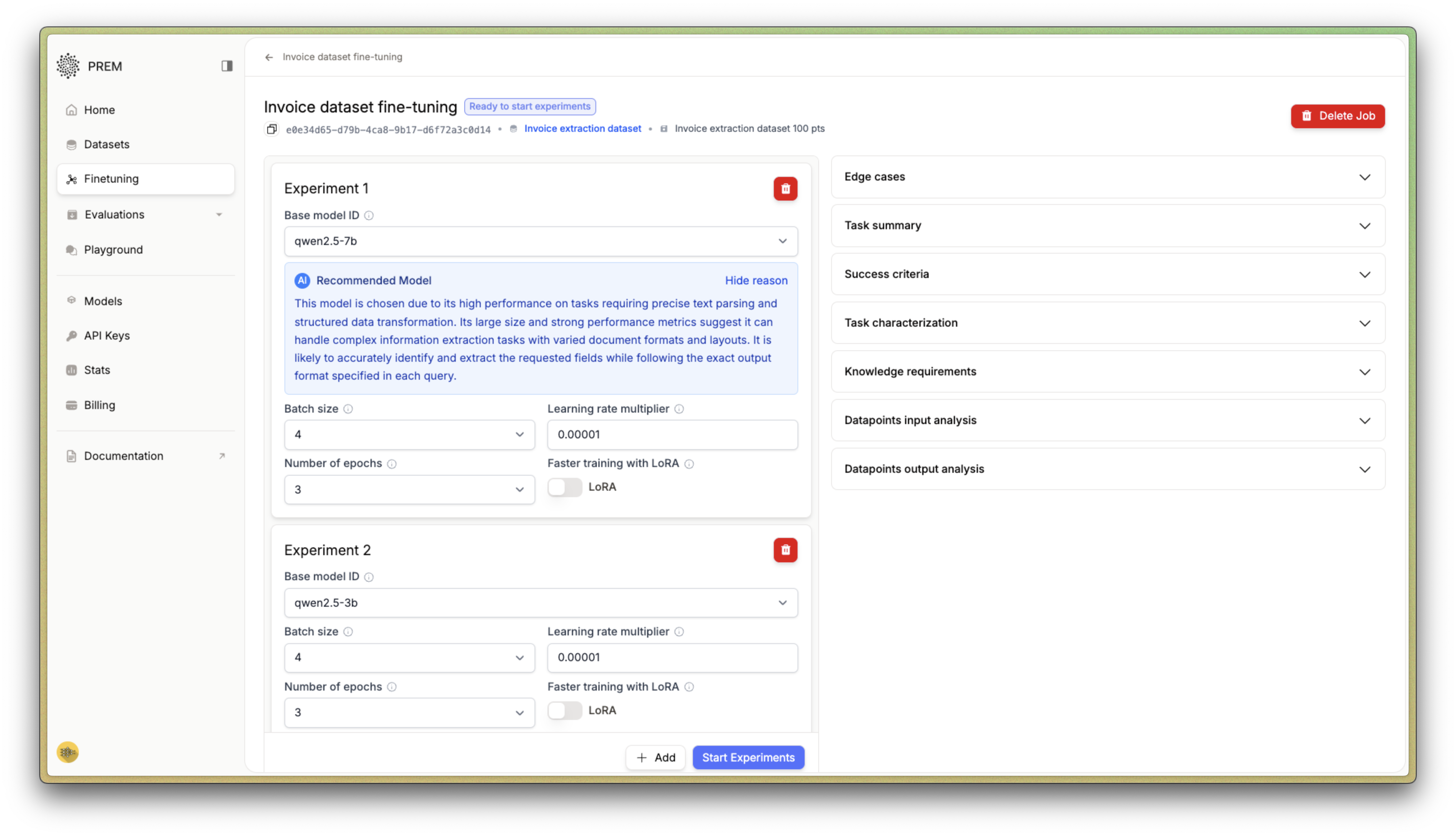
Customizing Your Experiment
You can customize your fine-tuning experiment by:- Adjusting hyperparameters: Modify batch size, epochs, and learning rate (we recommend keeping the default values for optimal results)
- Adding multiple models: Click + Add to include additional model variants in your experiment
- Choosing fine-tuning method: Select between LoRA and full fine-tuning
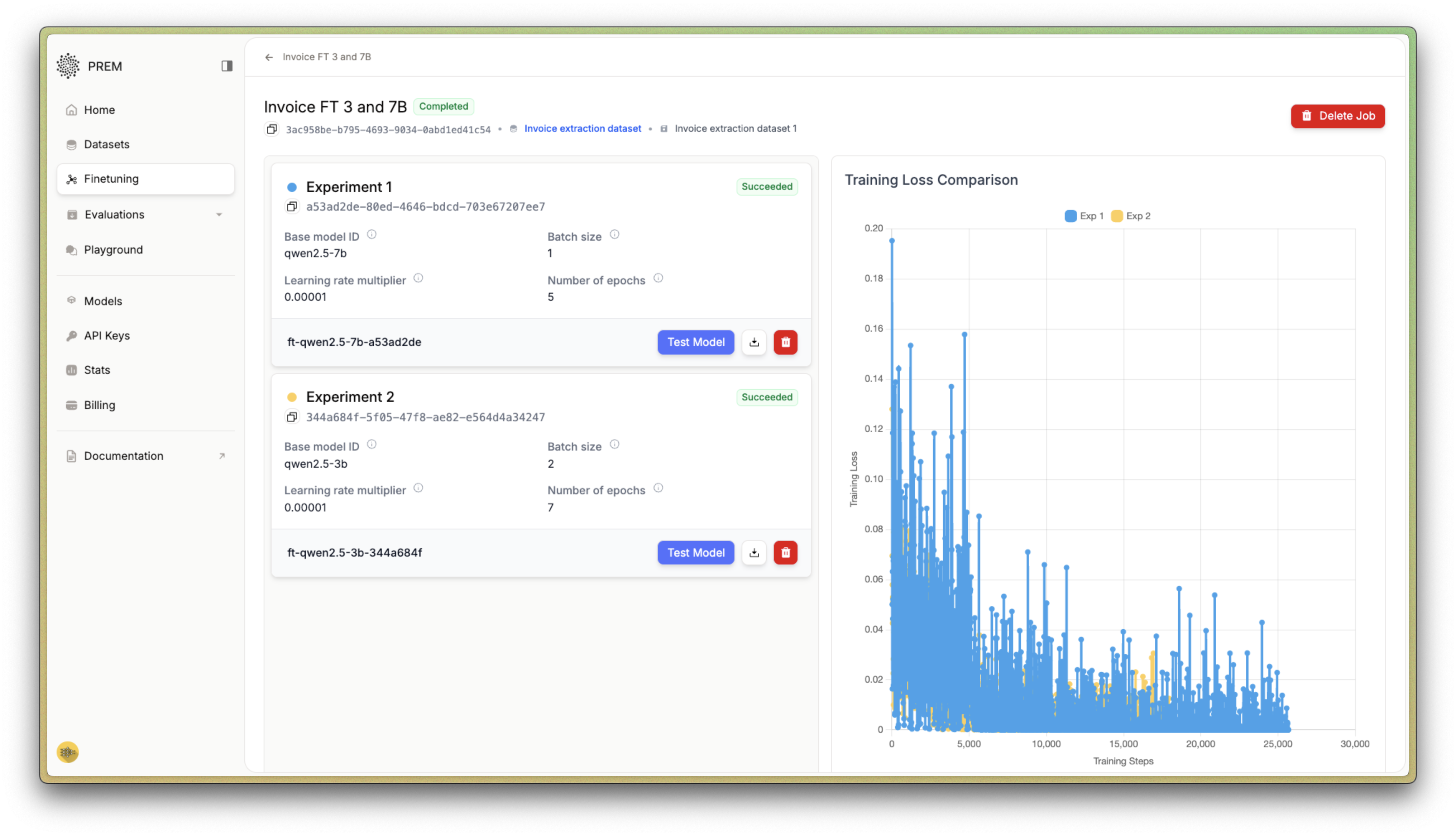
Evaluating Model Performance
Prem’s Agentic Evaluation system allows you to establish custom quality checks for your models using natural language descriptions, even without extensive testing infrastructure.Learn more about Prem’s evaluation capabilities in our evaluation overview.
Creating Custom Metrics
Navigate to the Metrics section and click + Create Metric. For our invoice parsing evaluation, we define the following criteria: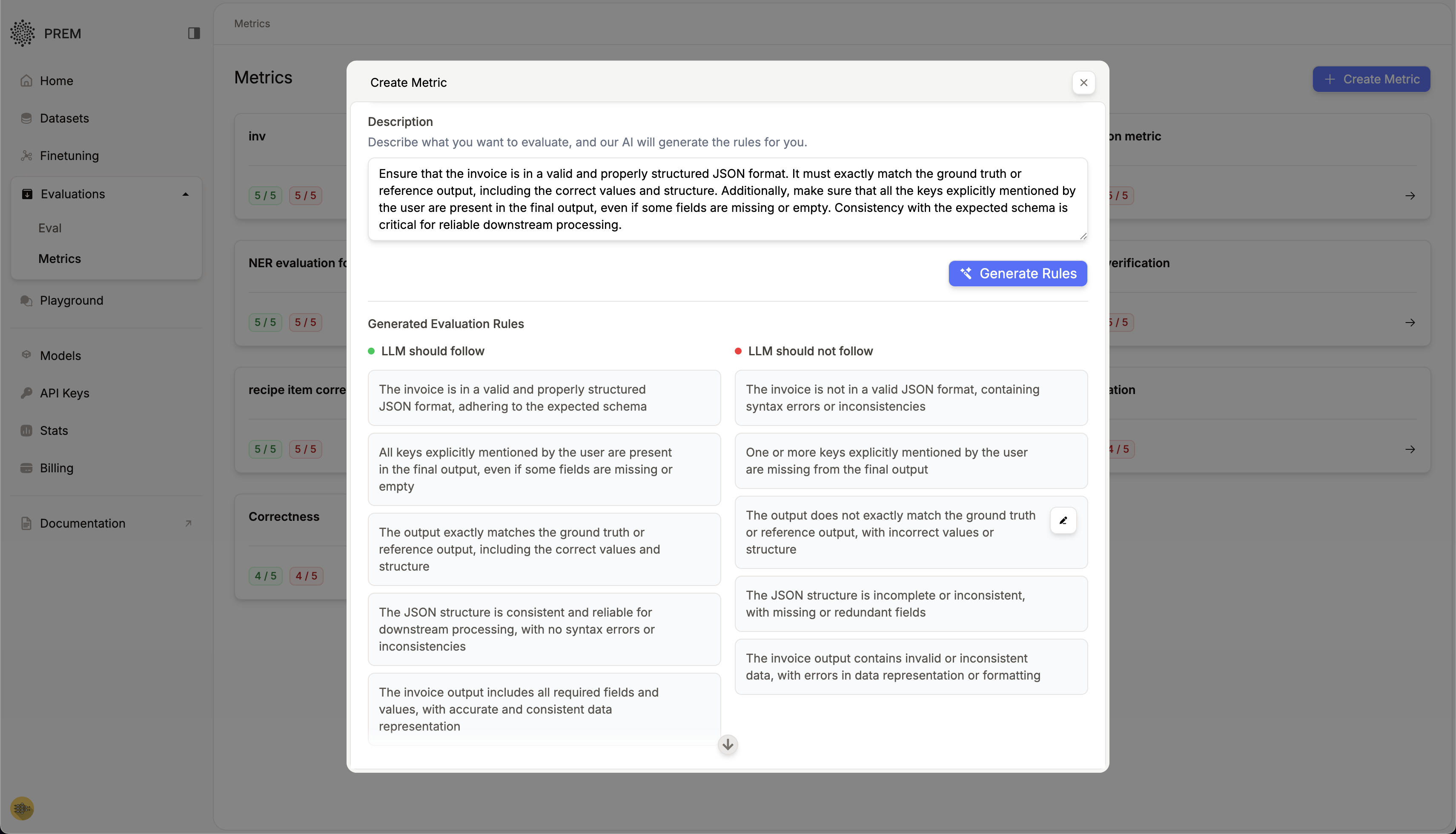
Running the Evaluation
Configure your evaluation by selecting:- Models to evaluate: GPT-4o, GPT-4o-mini, and all our Prem fine-tuned Qwen models
- Dataset snapshot: The validation dataset we created earlier
- Metrics: Prem’s built-in metrics (Conciseness, Hallucination) plus our custom “Invoice Verification” metric
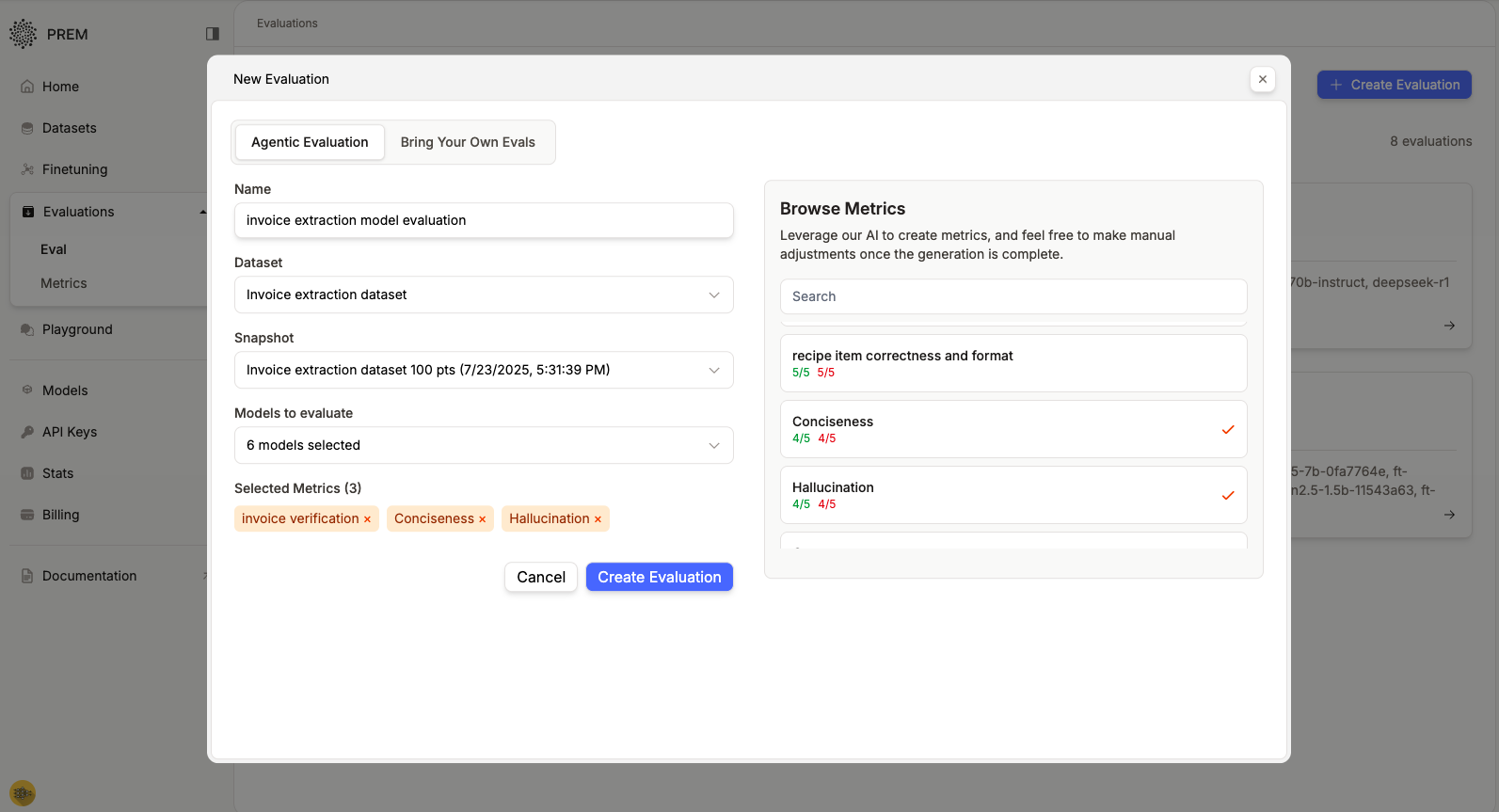
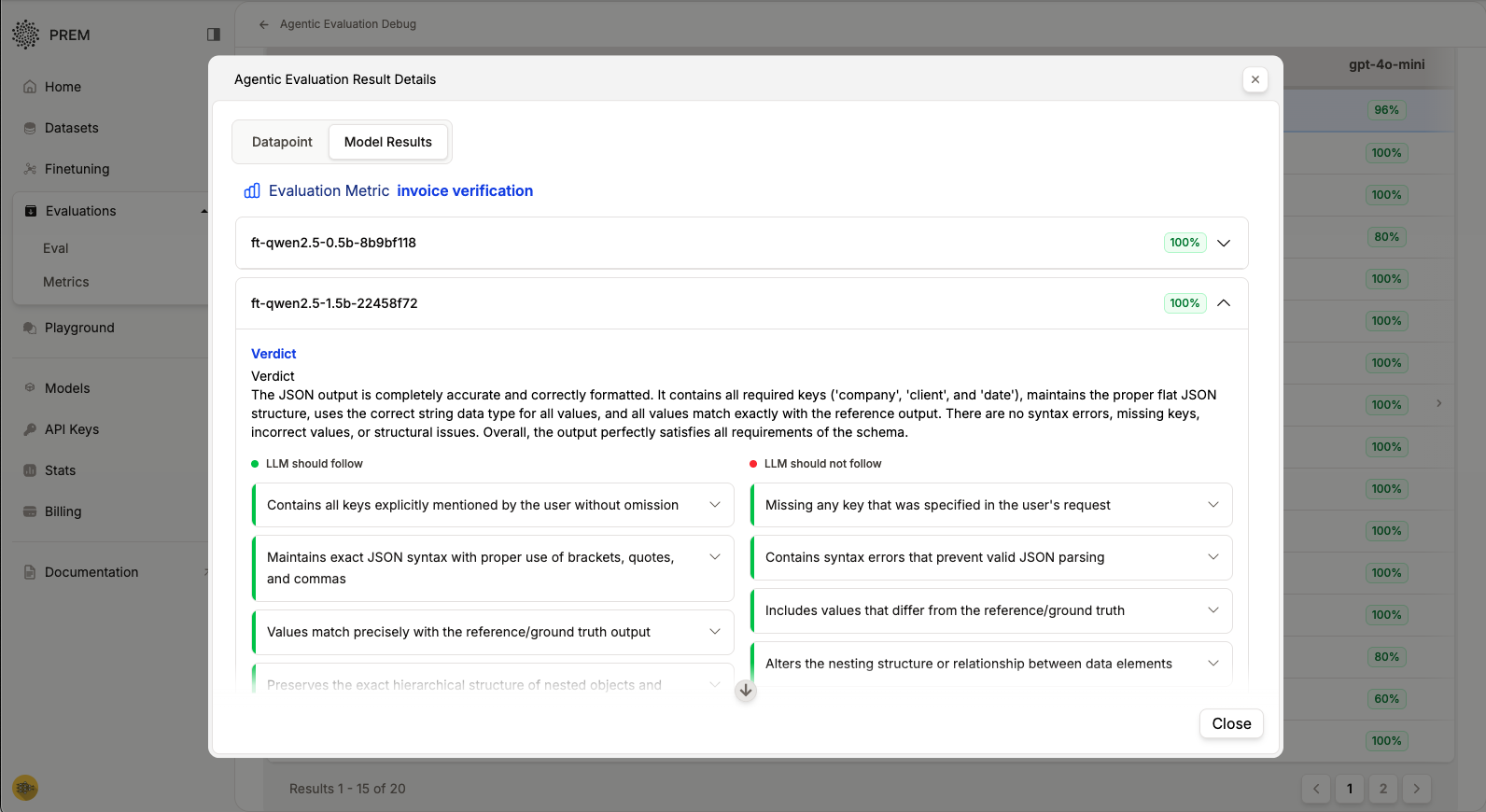
Understanding Evaluation Results
Once evaluation completes, you’ll see comprehensive results: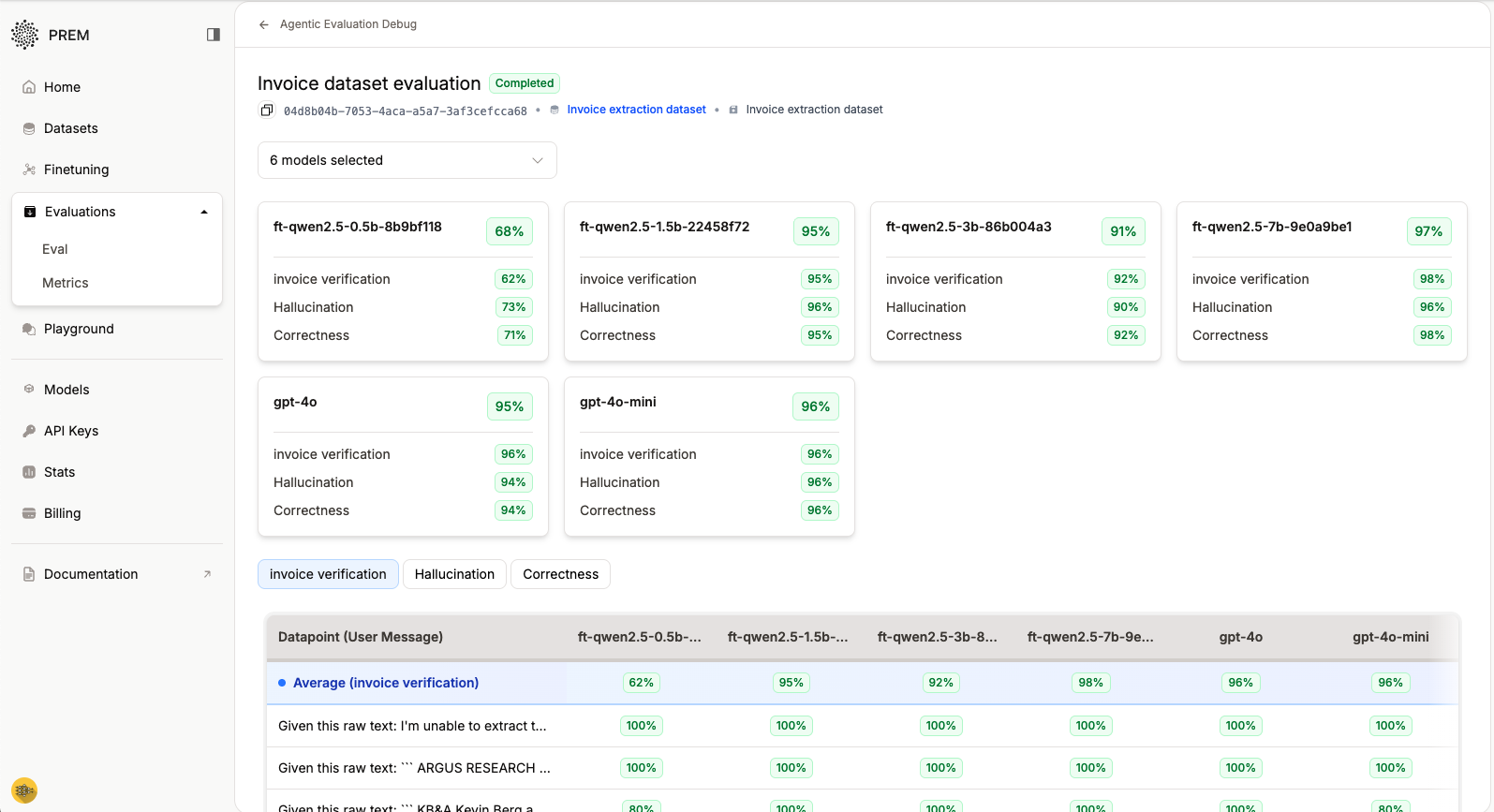
Interpreting the Results
The evaluation interface provides:- Evaluation Leaderboard: Overall performance summary across all models and metrics
- Detailed Metric Tables: Separate tabs for each evaluation metric
- Individual Datapoint Analysis: Click any row to see detailed results
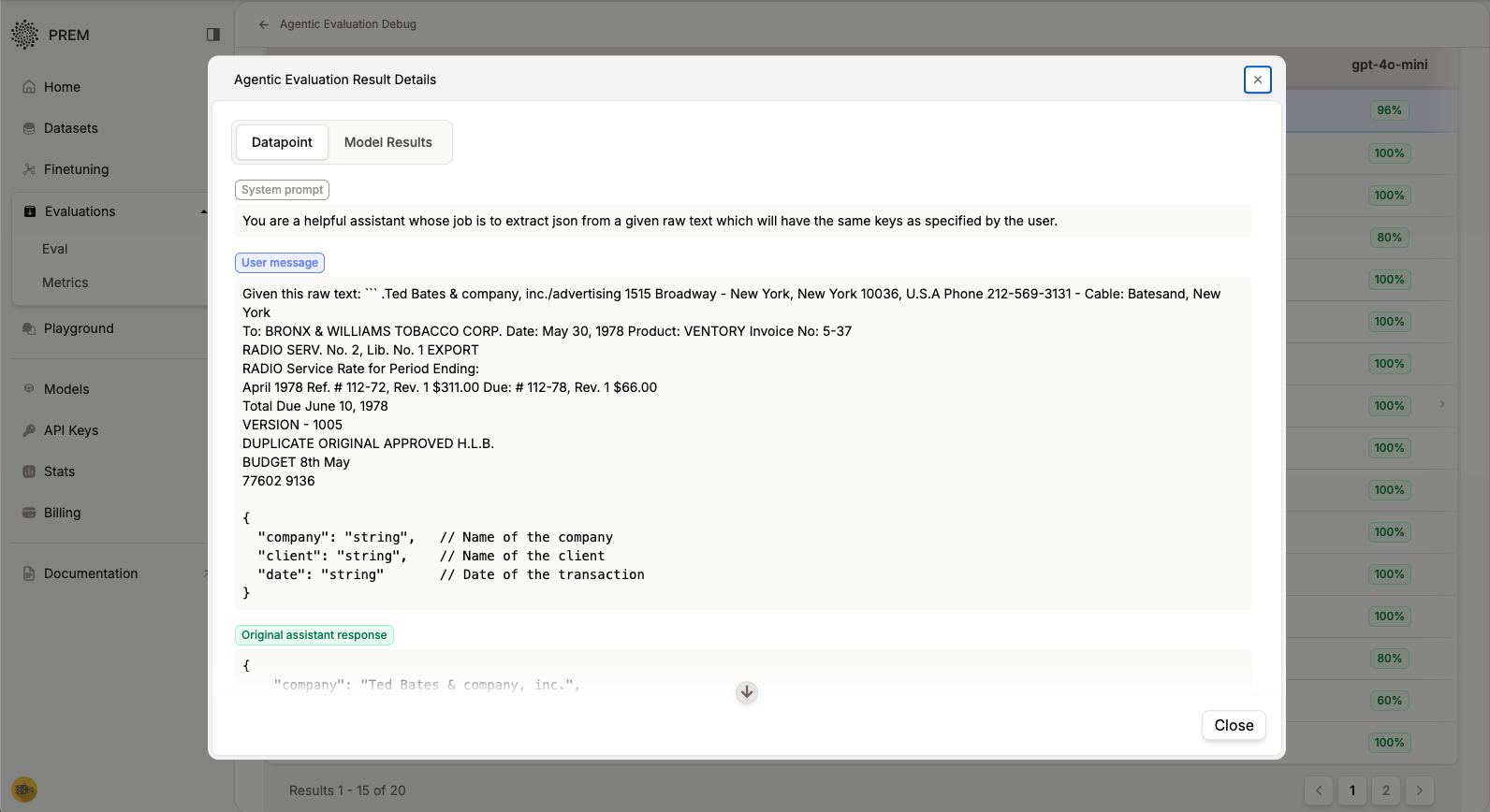
Testing in Prem Playground
While evaluations are running or after completion, you can empirically test your model in the Prem Playground: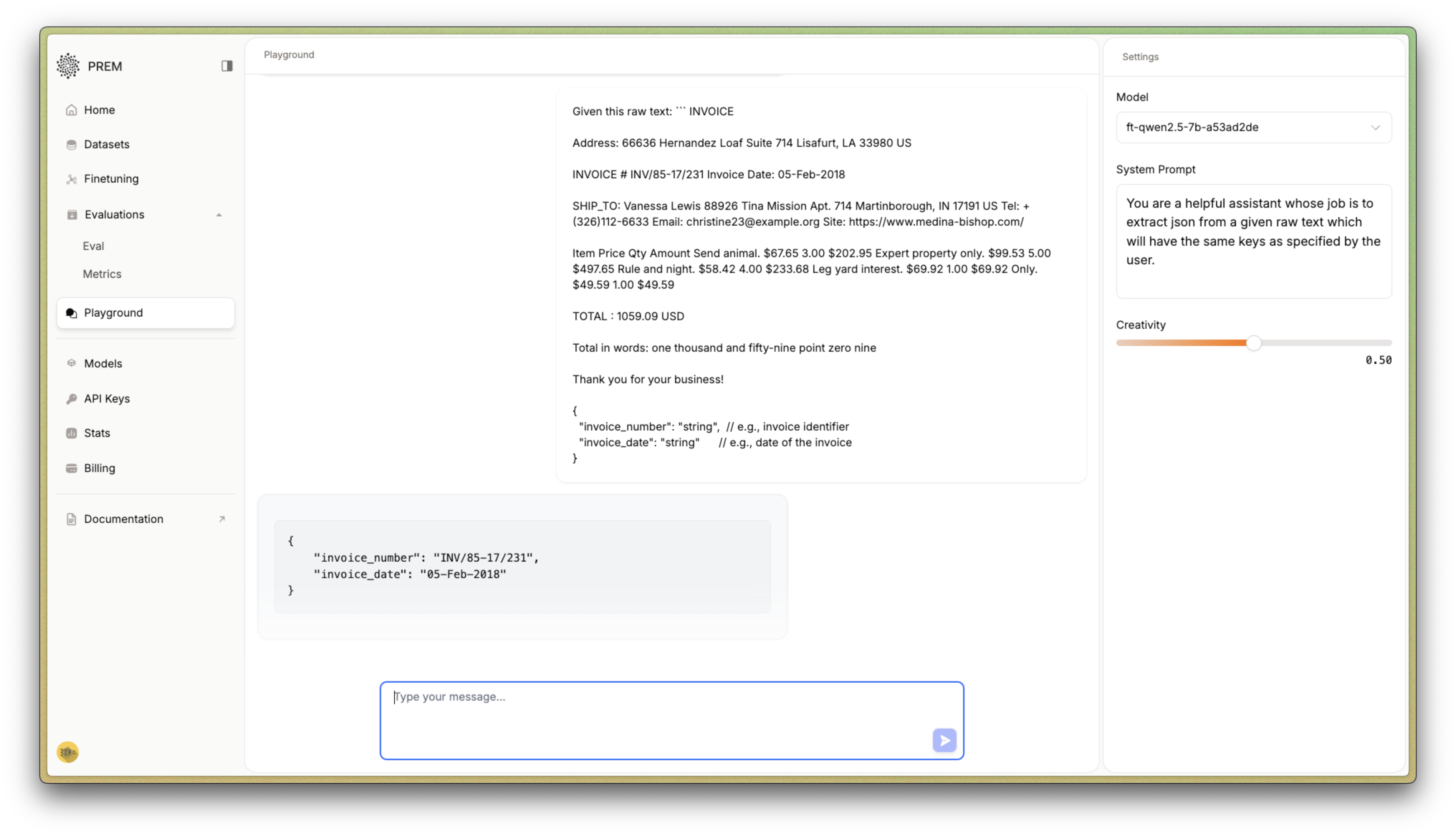
Learn more about using the playground effectively in our playground overview.
Deployment and Cost Analysis
Production Deployment
Prem models are automatically deployed on Prem’s infrastructure, eliminating deployment complexity. For custom infrastructure needs, you can download the fine-tuned model weights for self-hosting. Here’s how to use your fine-tuned model in production:Cost Comparison Analysis
Serving fine-tuned models at scale in production pipelines can become prohibitively expensive with OpenAI, where inference costs reach$15.00 per million output tokens for GPT-4o and $1.20 for GPT-4o-mini.
In contrast, Prem offers flat inference rates for any hosted or fine-tuned model that are extremely economical:
| Model Type | Input (per 1M tokens) | Output (per 1M tokens) | Total Inference Cost |
|---|---|---|---|
| Prem SLM (all sizes) | $0.10 | $0.30 | $0.40 |
| OpenAI GPT-4o | $5.00 | $15.00 | $20.00 |
| OpenAI GPT-4o-mini | $0.30 | $1.20 | $1.50 |
Real-World Savings Example
For an inference server processing 10M tokens monthly:- Prem SLM: $4.00 total
- GPT-4o-mini: $15.00 total
- GPT-4o: $200.00 total
Next Steps
Now that you’ve seen how to achieve better performance at lower costs, consider exploring:- Uploading your models to Hugging Face for broader distribution
- Advanced fine-tuning techniques for other use cases
- Custom evaluation strategies for your specific domain
This example demonstrates the complete Prem workflow from data preparation through production deployment. The same principles apply to other domain-specific tasks where fine-tuned models can deliver superior performance at significantly lower costs than general-purpose APIs.