

🧠 Why This Matters
A small dataset can limit a model’s ability to generalize and perform well on unseen data — especially in domain-specific tasks. With Prem Studio, you can enrich your dataset using synthetic data generation strategies. This allows you to:- 📈 Expand your dataset size with low human effort
- 🧠 Introduce diversity into training examples
- 🚀 Improve model performance and generalization during fine-tuning
- 🧪 Prototype quickly, even with minimal real data
💼 Use Case: Fine-Tuning a Customer Support Chatbot
Imagine you’re building a domain-specific chatbot to answer product-related queries for an e-commerce company. You’ve collected only 50 QA pairs from past support tickets — not enough for robust fine-tuning. Instead of manually creating more data, you can enrich your dataset using synthetic generation in Prem Studio. This guide shows you how.⚙️ Step-by-Step: Enrich Your Dataset with Synthetic Data
1
Select Your Dataset and Perform a 50/50 Split
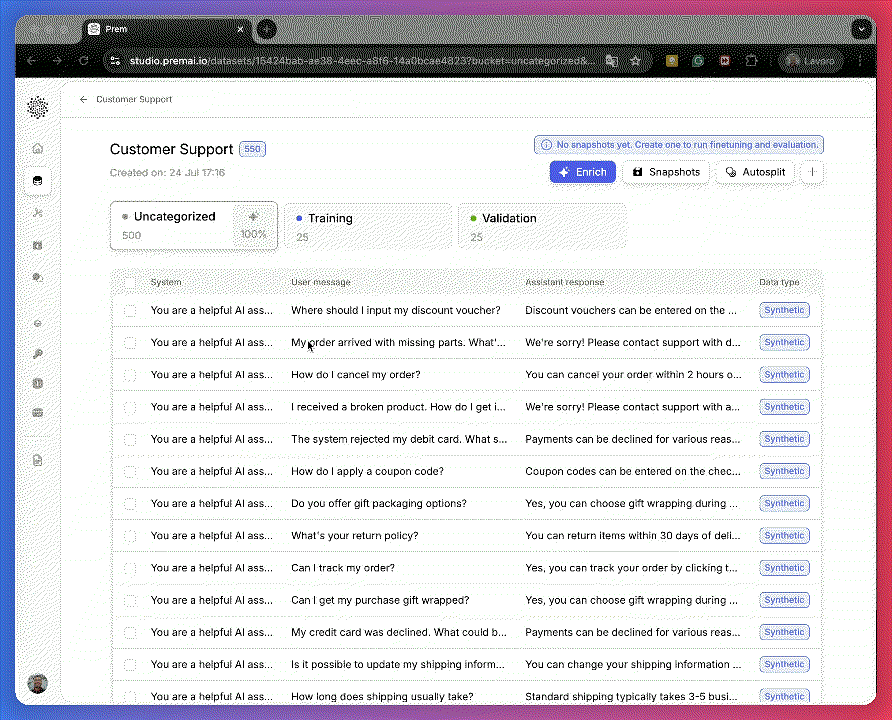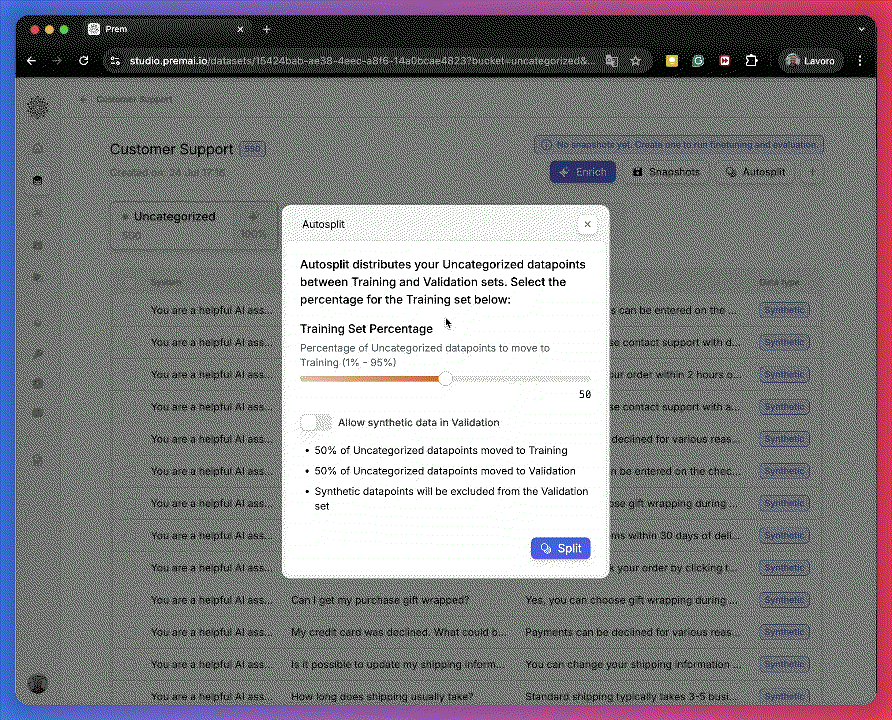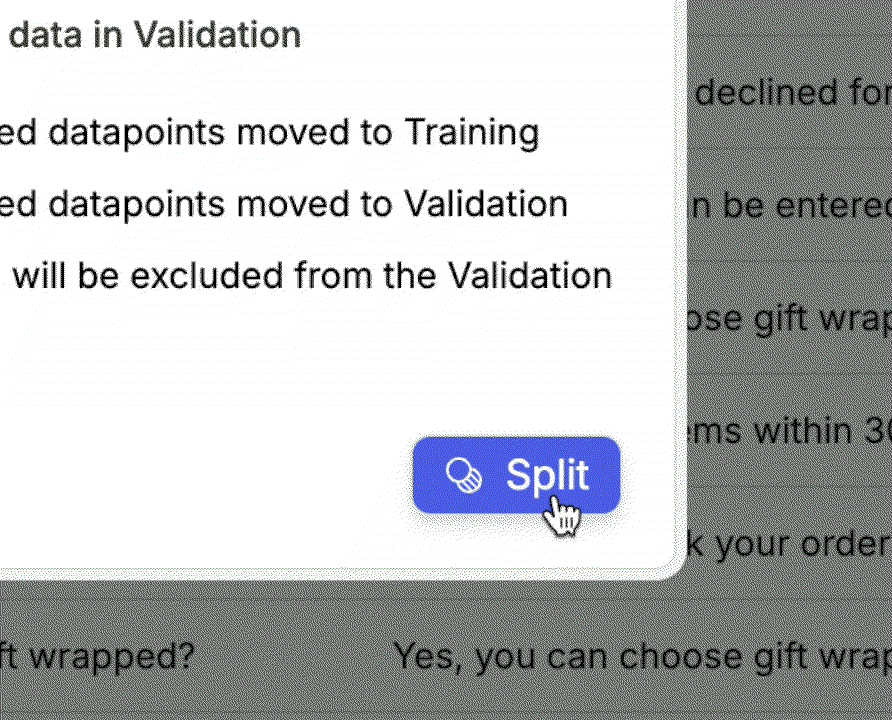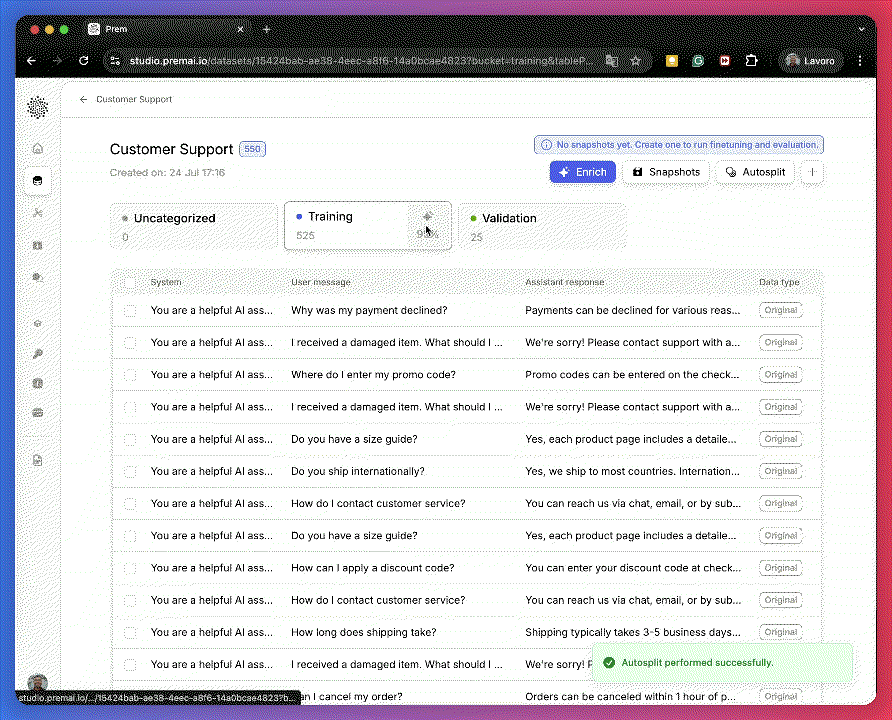
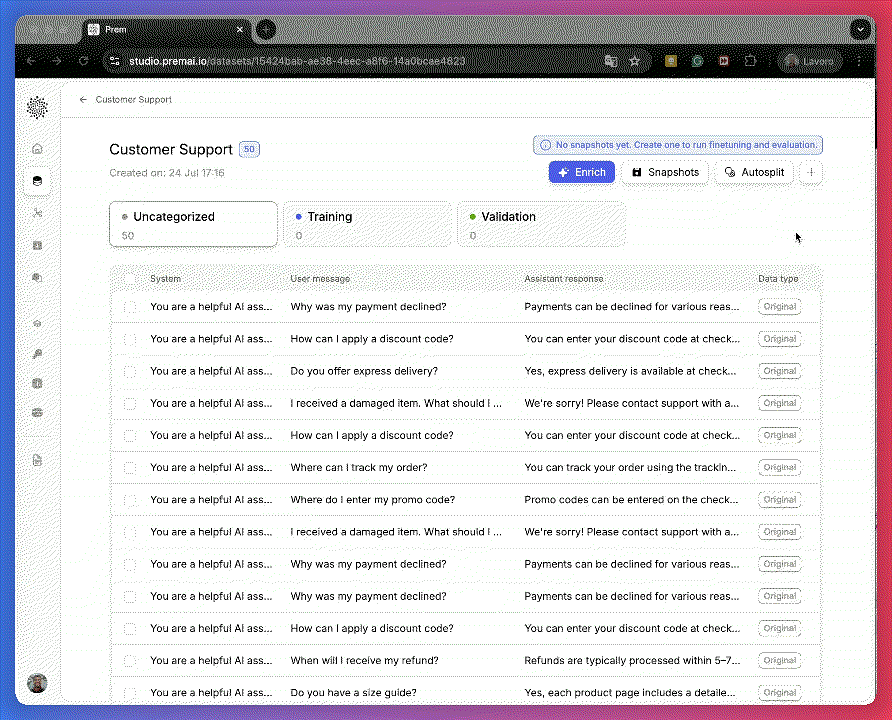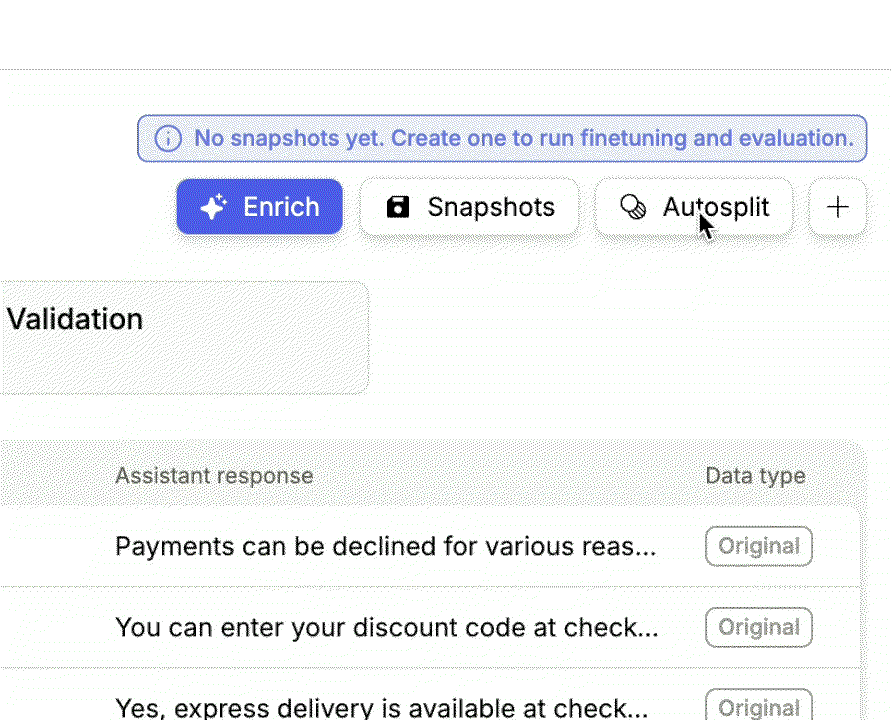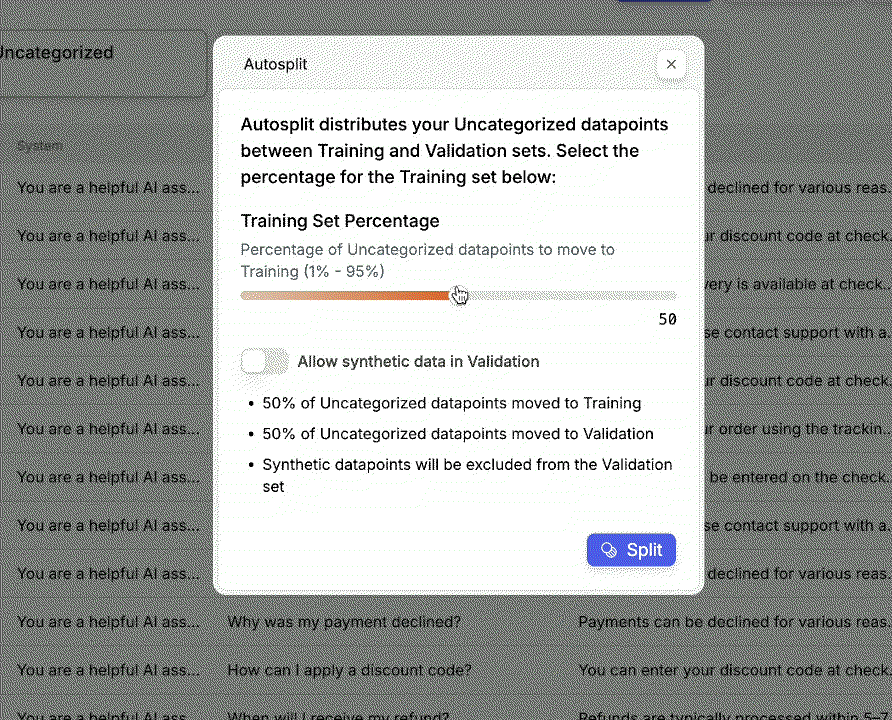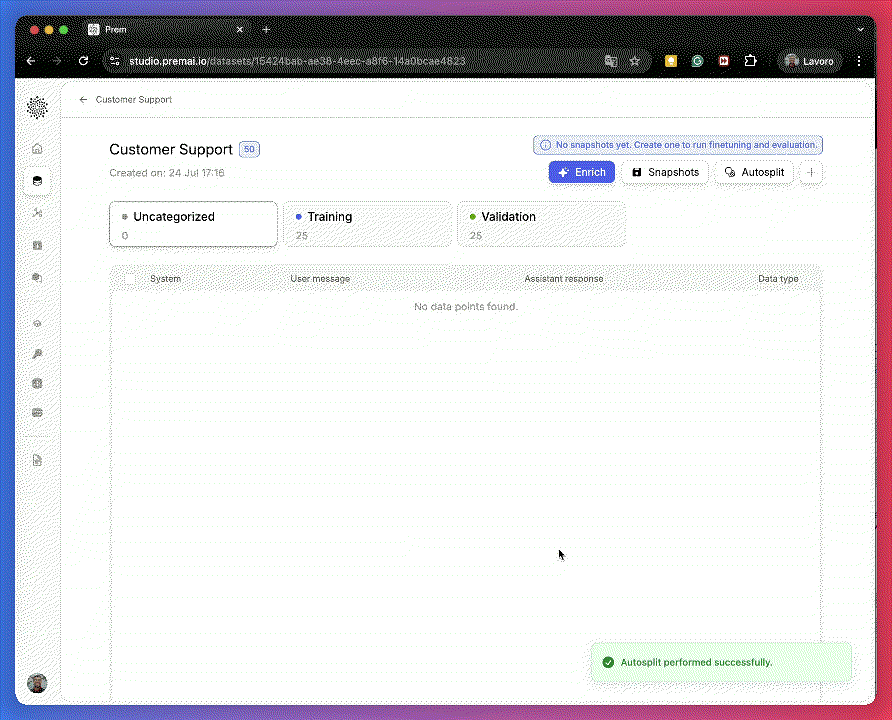 From the sidebar, go to Datasets and open your 50-row dataset.Split it 50/50: 25 datapoints for training and 25 for validation.
This ensures your evaluation is based on a meaningful validation size, despite the small dataset.Only examples in the Training and Uncategorized buckets will be used during enrichment.
From the sidebar, go to Datasets and open your 50-row dataset.Split it 50/50: 25 datapoints for training and 25 for validation.
This ensures your evaluation is based on a meaningful validation size, despite the small dataset.Only examples in the Training and Uncategorized buckets will be used during enrichment.2
Launch the Enrichment Workflow
 In the top right corner, click Enrich Dataset. Then choose Seed data enhancement.
You’ll be enriching the 25 training datapoints to boost generalizability.
In the top right corner, click Enrich Dataset. Then choose Seed data enhancement.
You’ll be enriching the 25 training datapoints to boost generalizability.3
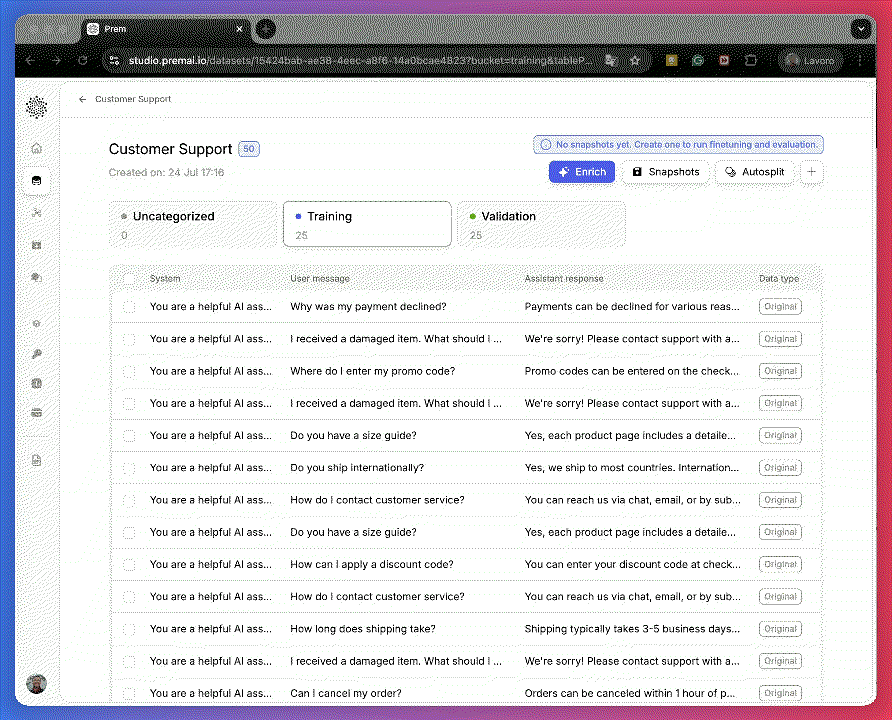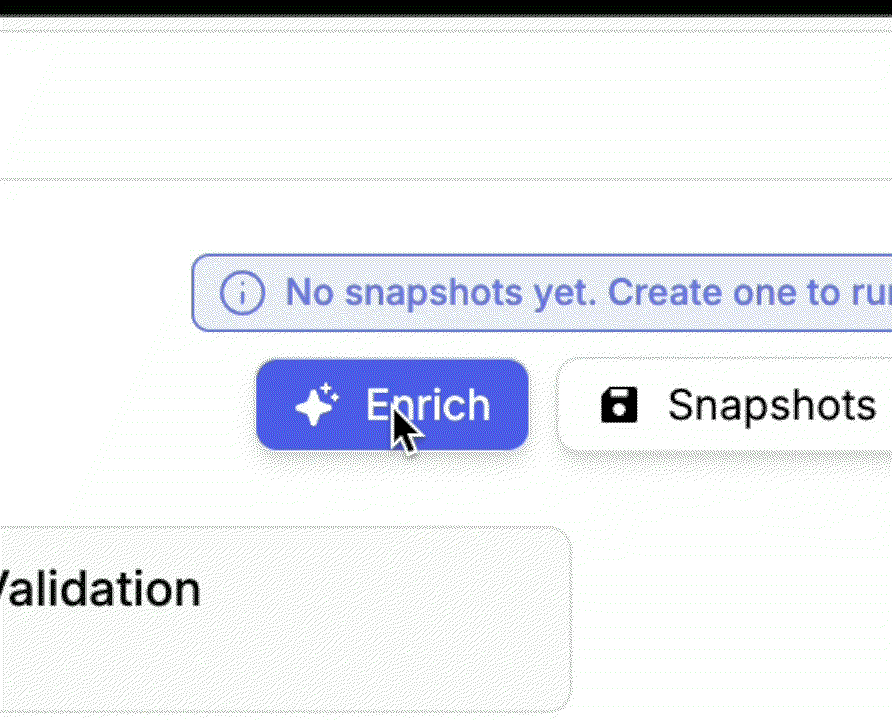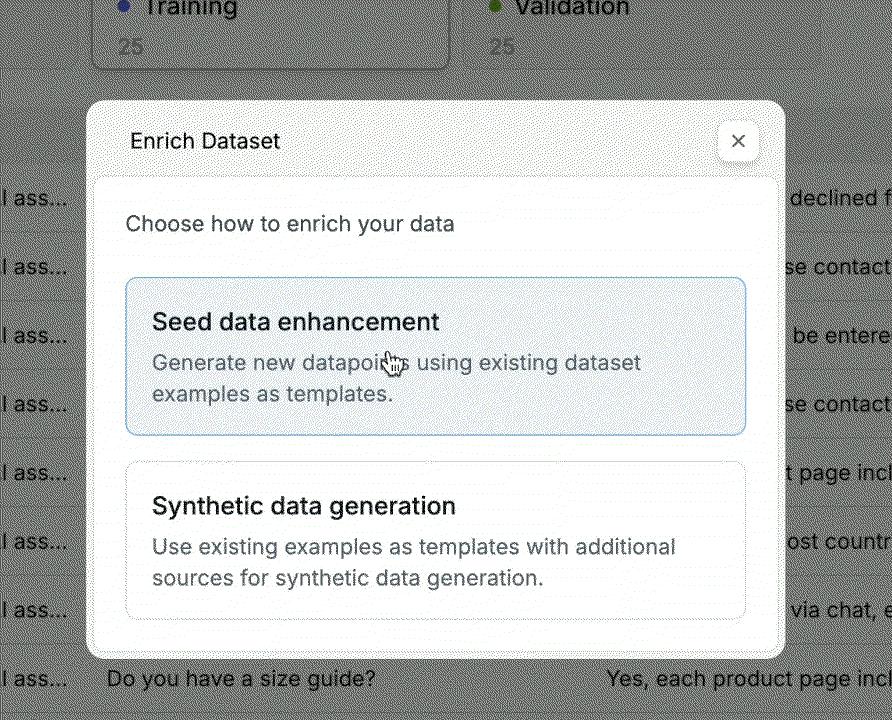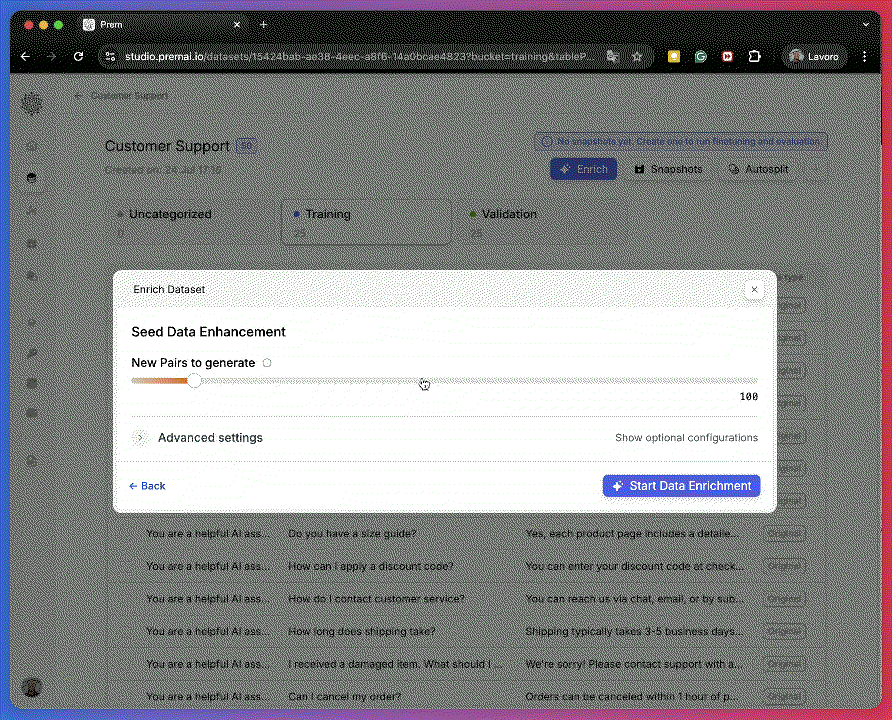
Define Enrichment Settings and (Optional) Instructions
 Set the following:
Set the following:- New pairs to generate:
500 - Creativity:
0.1(lower creativity = safer, more consistent results)
- Instructions (optional):
4
Review and Approve Synthetic Examples
Click Generate. Review the 500 synthetic examples.
Approve the ones you’d like to keep.
5
Add Synthetic Datapoint to Training Bucket
 In case the data quality matches your expectations, you can continue by adding all the datapoints to the Training bucket.
In case the data quality matches your expectations, you can continue by adding all the datapoints to the Training bucket.6
(Optional) Further Enrich Using Textual Documents
 You can optionally upload additional textual sources — such as PDFs, TXT files, or HTML pages — to provide contextual grounding for enrichment.These documents (e.g. product manuals, help center articles, policy pages) are used alongside your seed datapoints to generate more realistic and context-aware synthetic QA pairs.
You can optionally upload additional textual sources — such as PDFs, TXT files, or HTML pages — to provide contextual grounding for enrichment.These documents (e.g. product manuals, help center articles, policy pages) are used alongside your seed datapoints to generate more realistic and context-aware synthetic QA pairs.When documents are provided, the enrichment engine combines both seed examples and content from your uploaded files to create new, high-quality datapoints that better reflect your domain language and topics.
📊 Example Before and After Enrichment
| Type | Question | Answer |
|---|---|---|
| Original | How can I track my order? | You can track it using the link in your confirmation email. |
| Synthetic | Where do I check the status of my shipment? | Use the tracking link in the confirmation email we sent you. |
| Synthetic | Can I know where my package is? | Yes, the tracking link in your confirmation email shows real-time updates. |
📊 Dataset Size: Before vs After
Started with 50 original examples.- Split: 25 training / 25 validation
- After enrichment: +500 synthetic datapoints → 550 total (525 in training + 25 in validation)
📦 What’s Next?
With your enriched dataset, you can now:- Fine-tune a model with higher data diversity (Fine-Tuning Guide)
- Evaluate model generalization with agentic evaluation
💡 Pro Tips
- Always enrich after splitting to avoid data leakage.
- Use instructions to control output tone, complexity, topic, or QA structure.
- Review synthetic data for consistency — quality > quantity.
- Avoid over-relying on synthetic examples for evaluation.